Code
# !pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2 ![]()
“지각은 단일 감각의 파편이 아니라, 모든 감각이 조화롭게 융합된 교향곡이다.”, 제임스 깁슨, 생태심리학 창시자.
인공지능 역사에서 오랫동안 풀리지 않던 난제가 있었습니다. 바로 “멀티모달리티(Multimodality)” 입니다. 인간은 세상을 인식할 때 시각, 청각, 촉각 등 다양한 감각(modality)을 동시에 사용하고, 이들을 유기적으로 통합합니다. 예를 들어, 우리는 카페에서 커피를 마실 때 커피 잔의 따뜻함(촉각), 커피 향(후각), 주변 사람들의 대화 소리(청각), 카페 내부의 풍경(시각) 등 다양한 정보를 동시에 받아들이고, 이를 통해 “카페에 있다”는 하나의 총체적인 경험을 형성합니다.
하지만 초기 인공지능 모델은 이러한 멀티모달 정보를 처리하는 데 어려움을 겪었습니다. 1950년대부터 시작된 인공지능 연구는 주로 단일 모달리티(텍스트, 이미지, 음성) 처리에 집중했습니다. 각 분야에서 번역, 음성 인식등 괄목할 만한 성과가 있었지만, 이들을 통합하여 인간처럼 이해하는 것은 또 다른 차원의 문제였습니다.
이 장에서는 멀티모달 딥러닝의 핵심 이론과 살아남은 아키텍처들을 심도 있게 탐구합니다. 각 아키텍처가 어떤 방식으로 딥러닝의 DNA를 확장하고 진화시켰는지, 그리고 이들이 어떻게 현실 세계의 복잡한 문제를 해결하는 데 기여하고 있는지 살펴볼 것입니다.
도전 과제: 텍스트, 이미지, 오디오 등 서로 다른 형태의 데이터를 어떻게 하나의 모델에서 통합하여 처리할 것인가? 이들 데이터는 표현 방식, 차원, 통계적 특성이 모두 다르다. 어떻게 이질적인 정보를 융합하여 의미 있는 표현을 학습할 것인가?
연구자의 고뇌: 연구자들은 각 모달리티의 고유한 특성을 유지하면서도, 이들 간의 상호작용을 효과적으로 모델링할 수 있는 새로운 방법, 즉 딥러닝의 새로운 DNA를 찾아야 했습니다. 단순한 결합(concatenation)을 넘어, 각 모달리티가 서로의 맥락을 이해하고 상호 보완적인 정보를 제공하는 진정한 의미의 융합이 필요했습니다.
멀티모달 데이터는 텍스트, 이미지, 오디오, 비디오 등 두 가지 이상의 서로 다른 형태의 데이터가 결합된 것을 의미합니다. 예를 들어, 뉴스 기사는 텍스트와 이미지로, 영화는 비디오와 오디오로 구성됩니다. 인간은 이러한 멀티모달 정보를 자연스럽게 통합하여 세상을 이해합니다. 단어를 읽으면서 동시에 그림을 보고, 소리를 들으면서 상황을 파악하는 것은 인간에게는 지극히 당연한 일입니다.
왜 멀티모달 딥러닝은 어려운 문제였을까?
이질적인 데이터 표현: 텍스트, 이미지, 오디오는 표현 방식, 차원, 통계적 특성이 모두 다릅니다. 이러한 이질적인 데이터를 어떻게 하나의 모델에서 효과적으로 표현하고 처리할 것인가는 어려운 문제였습니다.
정보 융합의 복잡성: 각 모달리티의 정보를 단순히 결합하는 것(concatenation)은 진정한 의미의 융합이라고 할 수 없습니다. 각 모달리티가 서로의 맥락을 이해하고, 상호 보완적인 정보를 제공하며, 때로는 상충되는 정보를 조율하는 복잡한 상호작용을 모델링해야 합니다.
데이터 부족과 불균형: 멀티모달 데이터는 단일 모달리티 데이터에 비해 상대적으로 양이 적고, 각 모달리티 간의 데이터 불균형 문제도 존재합니다. 예를 들어, 이미지와 텍스트가 쌍으로 이루어진 데이터는 많지만, 이미지, 텍스트, 오디오가 모두 함께 존재하는 데이터는 훨씬 적습니다.
이러한 난제에도 불구하고, 딥러닝은 이러한 멀티모달 데이터 처리에 새로운 차원의 가능성을 제시했습니다.
2010년대 이후 딥러닝 기술의 발전, 특히 트랜스포머(Transformer) 아키텍처의 등장은 멀티모달 딥러닝 발전에 결정적인 역할을 했습니다. 이는 딥러닝 DNA의 중요한 변곡점이었습니다. 트랜스포머의 셀프 어텐션(self-attention) 메커니즘은 각 모달리티 내의 요소 간 관계뿐만 아니라, 서로 다른 모달리티 간의 복잡한 상호작용까지 효과적으로 모델링할 수 있게 했습니다. 이전까지는 CNN이 이미지, RNN이 시퀀스 데이터 처리에 특화되어 있었다면, 트랜스포머는 범용적인(universal) 아키텍처로 다양한 모달리티에 적용될 수 있는 유연성을 제공했습니다.
멀티모달 딥러닝은 인공지능이 인간처럼 세상을 이해하고 상호작용하는 데 필수적인 기술입니다. 이는 단순히 여러 형태의 데이터를 처리하는 것을 넘어, 각 데이터가 담고 있는 의미를 유기적으로 연결하여 더 풍부하고 정확한 추론을 가능하게 합니다. 마치 뇌의 여러 영역이 협력하여 복잡한 인지 기능을 수행하는 것처럼, 멀티모달 딥러닝은 인공지능의 지능을 한 단계 끌어올리는 핵심 동력입니다.
주요 응용 분야
시각 질의응답 (Visual Question Answering, VQA): 이미지와 질문(텍스트)을 입력받아 질문에 대한 답변을 생성합니다. 단순히 이미지 속 객체를 인식하는 것을 넘어, 이미지와 질문의 의미를 종합적으로 이해해야 합니다. 예를 들어, “그림 속 남자는 어떤 색깔의 모자를 쓰고 있는가?”라는 질문에 답하기 위해서는 남자를 찾고, 모자를 인식하고, 색깔을 판별하는 복합적인 과정이 필요합니다.
이미지 캡셔닝 (Image Captioning): 이미지를 설명하는 텍스트를 자동으로 생성합니다. 이미지의 내용을 정확하게 파악하고, 이를 자연스러운 문장으로 표현해야 합니다.
멀티모달 감정 분석 (Multimodal Sentiment Analysis): 텍스트, 음성, 표정 등 여러 정보를 종합하여 사용자의 감정을 파악합니다. 텍스트만으로는 파악하기 어려운 비꼬는 말투나 미묘한 감정 변화를 음성 톤이나 표정 변화를 통해 감지할 수 있습니다.
자율 주행: 카메라(이미지), LiDAR(3D 센서), GPS(위치 정보), 레이더 등 다양한 센서 데이터를 통합하여 주변 환경을 인식하고 주행 결정을 내립니다. 각 센서는 서로 다른 정보를 제공하며, 이들을 융합해야만 안전하고 정확한 주행이 가능합니다.
로봇 공학: 로봇이 시각, 촉각, 청각 등 다양한 센서 정보를 융합하여 복잡한 작업을 수행합니다. 예를 들어, 로봇이 물건을 잡기 위해서는 물체의 위치와 형태를 시각적으로 파악하고, 물건을 잡았을 때의 촉각 정보를 통해 적절한 힘을 조절해야 합니다.
의료 진단: X-ray, MRI(이미지), 환자 기록(텍스트), 생체 신호(시계열 데이터), 유전체 정보 등을 종합하여 질병을 진단하고 예측합니다. 각 데이터는 질병에 대한 서로 다른 단서를 제공하며, 이들을 통합적으로 분석해야 정확한 진단이 가능합니다.
멀티모달 딥러닝 연구는 딥러닝 DNA의 진화를 보여주는 흥미로운 여정입니다. 이 여정은 크게 다음과 같은 주요 단계로 나누어 살펴볼 수 있습니다.
2010년대 초반, 멀티모달 딥러닝의 초기 연구는 주로 이미지 캡셔닝(image captioning)과 VQA(Visual Question Answering)에 집중되었습니다. 이 시기에는 CNN(Convolutional Neural Network)을 사용하여 이미지에서 특징을 추출하고, RNN(Recurrent Neural Network)을 사용하여 텍스트를 처리하는 CNN-RNN 기반 모델이 주를 이루었습니다. CNN은 이미지의 공간적인 특징을 효과적으로 포착하고, RNN은 텍스트의 순차적인 정보를 처리하는 데 강점을 보였습니다.
하지만 초기 모델들은 각 모달리티를 독립적으로 처리한 후 마지막 단계에서 결과를 결합하는 late fusion 방식을 주로 사용했습니다. 이 방식은 각 모달리티의 고유한 특성을 보존할 수 있다는 장점이 있었지만, 모달리티 간의 초기 단계에서의 상호작용을 충분히 반영하지 못한다는 한계가 있었습니다.
이 시기의 대표적인 모델로는 이미지와 단어 임베딩을 같은 공간에 투영하여 이미지-텍스트 간 유사도를 계산하는 DeViSE (Frome et al., 2013), 이미지 캡셔닝을 위해 CNN과 RNN을 결합하고 멀티모달 정보를 융합하는 계층(multimodal layer)을 추가한 m-RNN (Mao et al., 2014) 등이 있습니다.
2010년대 중반, 어텐션 메커니즘(attention mechanism)의 등장은 멀티모달 딥러닝 연구에 큰 전환점을 가져왔습니다. 어텐션 메커니즘은 이미지와 텍스트 간의 관련성을 더욱 정교하게 모델링할 수 있도록 해주었습니다. 예를 들어, 이미지 캡셔닝에서 어텐션은 특정 단어를 생성할 때 이미지의 어떤 영역에 “주목”해야 하는지를 학습할 수 있게 하였고, VQA에서는 질문에 답하기 위해 이미지의 어떤 부분을 봐야 하는지를 결정하는 데 도움을 주었습니다.
어텐션 메커니즘의 도입은 이미지 캡셔닝과 VQA 모델의 성능을 크게 향상시켰습니다. 대표적인 모델로는 이미지 캡셔닝에 어텐션을 도입하여 생성되는 단어와 관련된 이미지 영역에 집중하도록 한 Show, Attend and Tell (Xu et al., 2015), VQA에서 질문에 대한 답변을 생성하기 위해 이미지에 여러 번 어텐션을 적용하는 Stacked Attention Networks (Yang et al., 2016) 등이 있습니다.
2017년, “Attention is All You Need” 논문에서 트랜스포머(Transformer) 아키텍처가 소개되면서 멀티모달 딥러닝은 새로운 국면을 맞이했습니다. 트랜스포머는 셀프 어텐션(self-attention) 메커니즘을 기반으로 하여 입력 시퀀스 내의 모든 요소 간의 관계를 직접적으로 모델링할 수 있다는 장점을 가졌습니다.
ViT (Vision Transformer, 2020): 이미지를 패치(patch)로 나누어 트랜스포머에 입력하는 ViT는 이미지 처리 분야에서 CNN의 강력한 대안으로 떠올랐습니다. ViT는 이미지 내의 장거리 의존성(long-range dependency)을 효과적으로 모델링하여 이미지 분류 등 다양한 태스크에서 뛰어난 성능을 보였습니다.
CLIP (Contrastive Language-Image Pre-training, 2021): CLIP은 대규모 이미지-텍스트 쌍 데이터를 사용하여 이미지와 텍스트를 같은 공간에 임베딩하는 방법을 학습했습니다. 이를 통해 별도의 fine-tuning 없이도 다양한 downstream task(이미지 분류, 객체 검출 등)에서 zero-shot(별도의 학습 없이 바로 적용)으로 뛰어난 성능을 보이는 획기적인 결과를 보여주었습니다.
DALL-E (2021), Imagen (2022), Stable Diffusion (2022): 텍스트 설명을 기반으로 고품질 이미지를 생성하는 모델들은 트랜스포머 기반 생성 모델의 놀라운 능력을 보여주었습니다. 이들은 텍스트와 이미지 간의 복잡한 관계를 학습하여, 이전에 상상하기 어려웠던 수준의 이미지 생성 결과를 보여주었습니다.
GPT-4V (2023), Gemini (2023): 텍스트와 이미지를 동시에 이해하고 처리하는 대규모 멀티모달 모델(LMM, Large Multimodal Model)의 등장은 멀티모달 딥러닝의 새로운 가능성을 열었습니다. 수십억 개의 파라미터를 가진 이 거대 모델들은 다양한 멀티모달 task에서 인간 수준의 성능을 달성하며, 인공지능 연구의 최전선에 서 있습니다.
최근 멀티모달 딥러닝 연구는 단순한 정보 융합을 넘어, 각 모달리티의 정보를 바탕으로 새로운 지식을 생성하고 추론하는 능력을 향상시키는 방향으로 발전하고 있습니다.
LMM (Large Multimodal Model)의 발전: 더 많은 모달리티(오디오, 비디오, 3D 센서 데이터 등)를 통합하고, 더 복잡한 추론 능력을 갖춘 LMM들이 계속해서 등장하고 있습니다.
효율적인 융합 기법 연구: 한편으로는, 제한된 컴퓨팅 자원에서도 멀티모달 모델을 효과적으로 활용하기 위해 계산 비용을 줄이면서도 정보 융합의 효과를 극대화하는 효율적인 융합 기법에 대한 연구도 활발히 진행되고 있습니다.
설명 가능성(XAI) 및 윤리적 문제: 멀티모달 모델의 복잡성이 증가함에 따라, 모델의 의사 결정 과정을 이해하고, 편향성 등 윤리적 문제를 해결하기 위한 연구의 중요성도 커지고 있습니다.
다음 절에서는 멀티모달 딥러닝의 초기 접근법들과, 그 과정에서 “살아남은” 주요 아키텍처를 좀 더 자세히 살펴보겠습니다.
10.1.3절에서 살펴본 것처럼, 트랜스포머와 CLIP은 멀티모달 딥러닝의 혁신을 가져왔습니다. 하지만 이러한 발전은 갑자기 이루어진 것이 아닙니다. 그 이전에도 이미지와 텍스트, 나아가 다양한 모달리티를 결합하려는 수많은 시도가 있었고, 이러한 초기 연구들이 현대 멀티모달 딥러닝의 탄탄한 기반을 다졌습니다. 이 절에서는 2010년대 초중반, 딥러닝 기반 멀티모달 연구의 초창기를 이끌었던 주요 접근법과 그 의의를 살펴보겠습니다.
이미지 캡셔닝(Image Captioning)은 주어진 이미지를 설명하는 자연어 문장(캡션)을 자동으로 생성하는 task입니다. 이는 이미지(시각 정보)를 텍스트(언어 정보)로 변환하는 대표적인 멀티모달 문제로, 딥러닝 기반 멀티모달 연구의 초기 주된 연구 대상이었습니다. 이미지 캡셔닝은 마치 어린아이가 그림책을 보면서 “여기에는 강아지가 있고, 저기에는 공이 있네!”라고 말하는 것과 유사합니다.
이미지 캡셔닝 연구 초기에는 CNN과 RNN을 결합한 모델이 주를 이루었습니다. 흡사 딥러닝이라는 뇌에 시각을 담당하는 CNN과 언어를 담당하는 RNN이라는 두 개의 반구를 연결하는 것과 같았습니다. CNN은 이미지 인코더로서 VGGNet, AlexNet 등을 사용하여 이미지의 특징 벡터를 추출했고, RNN은 텍스트 디코더로서 LSTM과 같은 모델을 사용하여 이미지 특징 벡터를 바탕으로 캡션 문장을 생성했습니다.
대표적인 모델로는 Show and Tell (Vinyals et al., 2015)이 있으며, 이 모델은 CNN으로 추출한 이미지 특징을 LSTM의 초기 hidden state로 입력하여 캡션을 생성하는 end-to-end 방식을 제안했습니다. 그러나 이러한 CNN-RNN 구조는 이미지의 전반적인 내용은 잘 파악했지만, 이미지의 세부적인 영역과 텍스트의 특정 단어 간의 대응 관계를 명확하게 모델링하지 못하는 한계가 있었습니다.
이미지의 특정 영역에 “주목”하는 어텐션 메커니즘은 이미지 캡셔닝 모델의 성능을 크게 향상시켰습니다. 어텐션은 마치 그림을 감상할 때 우리의 시선이 자연스럽게 중요한 부분으로 향하는 것과 같은 원리입니다.
어텐션 메커니즘에는 Soft Attention과 Hard Attention이 있습니다. Soft Attention은 이미지의 모든 영역에 대한 가중치를 계산하고 가중 평균된 특징 벡터를 사용하는 반면, Hard Attention은 이미지의 특정 영역 하나만을 선택하여 캡션을 생성합니다.
Show, Attend and Tell (Xu et al., 2015)은 Soft Attention 메커니즘을 이미지 캡셔닝에 처음으로 도입한 모델로, 캡션의 각 단어를 생성할 때마다 이미지의 어떤 영역에 주목해야 하는지를 학습하여 더 정확하고 상세한 캡션을 생성할 수 있게 되었습니다.
2017년 이후에는 이미지의 전체적인 맥락(top-down)과 개별 객체(bottom-up) 정보를 모두 활용하는 Bottom-Up and Top-Down Attention 방식이 등장했습니다. Bottom-up 접근법은 Faster R-CNN과 같은 객체 탐지 모델을 사용하여 이미지 내의 주요 객체들을 식별하고, Top-down 접근법은 캡션 생성 과정에서 이러한 객체 특징에 대한 어텐션 가중치를 계산합니다.
Bottom-Up and Top-Down Attention (Anderson et al., 2018) 모델은 이 두 접근법을 결합하여 이미지 캡셔닝 성능을 크게 향상시켰습니다. 이는 마치 전체적인 이야기의 흐름을 고려하면서, 각 장면에 등장하는 객체들을 상세히 묘사하는 것과 같습니다.
이미지 캡셔닝 연구는 딥러닝 DNA에 중요한 요소들을 추가했습니다. CNN-RNN 결합은 서로 다른 모달리티를 효과적으로 결합하는 기본적인 틀을 제시했고, 어텐션 메커니즘은 멀티모달 딥러닝에서 핵심적인 기술로 자리 잡았습니다. 또한 Bottom-Up and Top-Down Attention은 딥러닝 모델의 이미지 이해 능력을 한 단계 끌어올렸습니다.
이러한 발전은 이미지 캡셔닝을 넘어, 이후 VQA, 멀티모달 기계 번역 등 다양한 멀티모달 task로 확장되는 기반이 되었습니다. 최근에는 BLIP과 같은 트랜스포머 기반 모델이 등장하여, 이미지 캡셔닝뿐만 아니라 다양한 멀티모달 task에서 좋은 성능을 보이고 있습니다.
BLIP(Bootstrapping Language-Image Pre-training)은 이미지 캡셔닝을 위한 트랜스포머 기반 모델입니다. BLIP은 이미지와 텍스트를 함께 사전 학습하여, 이미지 캡셔닝뿐만 아니라 VQA, 이미지-텍스트 검색 등 다양한 멀티모달 task에서 좋은 성능을 보입니다.
다음은 Hugging Face Transformers 라이브러리를 사용하여 BLIP 모델로 이미지 캡션을 생성하는 예제 코드입니다.
# !pip install dldna[colab] # in Colab
# !pip install dldna[all] # in your local
%load_ext autoreload
%autoreload 2from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import requests
import matplotlib.pyplot as plt
# Load the model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# Download the image
url = "http://images.cocodataset.org/val2017/000000000632.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Display the image
plt.imshow(image)
plt.axis('off')
plt.show()
# Preprocess the input
inputs = processor(image, return_tensors="pt")
# Generate the caption
outputs = model.generate(**inputs)
# Decode and print the caption
caption = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated caption:", caption)
Generated caption: a bedroom with a bed and a window시각 질의응답(Visual Question Answering, VQA)은 이미지와 자연어 질문이 주어졌을 때, 이미지 내용을 바탕으로 질문에 대한 답변을 생성하는 task입니다. 이미지 캡셔닝이 이미지의 내용을 “묘사”하는 것이라면, VQA는 이미지에 대해 “질의응답”을 하는 것입니다. 예를 들어 “고양이는 뭘 먹고 있지?”라는 질문에 답을 하는 것입니다. VQA는 이미지 캡셔닝보다 더 복잡하고 고차원적인 이미지 이해 능력, 특히 이미지와 질문(텍스트) 간의 관계를 파악하고 추론하는 능력을 요구합니다.
이미지 캡셔닝과 마찬가지로, 초기 VQA 모델은 CNN과 RNN을 결합한 구조를 사용했습니다. CNN으로 이미지 특징을 추출하고, RNN으로 질문을 인코딩한 후, 이 두 특징을 결합하여 답변을 생성했습니다. 하지만 단순히 이미지 특징과 질문 특징을 결합하는 것만으로는 복잡한 질문에 답하기 어려웠습니다.
이미지 캡셔닝에서 어텐션 메커니즘이 성공을 거두면서, VQA에도 어텐션 메커니즘이 도입되었습니다. Co-Attention은 이미지와 질문 양쪽에 어텐션을 적용하여, 질문의 각 단어와 이미지의 각 영역 간의 관련성을 계산합니다. 이를 통해 질문에 관련된 이미지 영역을 더 정확하게 찾을 수 있습니다.
Stacked Attention은 어텐션을 여러 번 반복하여, 이미지와 질문 간의 복잡한 관계를 단계적으로 파악합니다. 이는 마치 탐정이 사진을 여러 번 훑어보면서 질문과의 관련성을 점차 깊이 이해하는 것과 같습니다.
대표적인 모델로는 Stacked Attention Networks (SAN) (Yang et al., 2016)와 Dual Attention Networks (DAN) (Nam et al., 2017)이 있습니다. SAN은 질문에 대한 답변을 생성하기 위해 이미지에 여러 번 어텐션을 적용하는 모델이고, DAN은 이미지와 질문 각각에 대한 어텐션을 별도로 계산하고, 이들을 결합하여 답변을 생성하는 모델입니다.
이미지 캡셔닝과 VQA의 가장 큰 차이는 외부지식 통합입니다. VQA 모델의 추론 능력을 더욱 향상시키기 위해 외부 지식(상식, 백과사전 지식 등)을 활용하는 연구가 진행되었습니다. Knowledge Base (KB)는 Wikipedia, ConceptNet 등 구조화된 지식 베이스를 활용하여, 질문에 대한 답변을 찾는 데 필요한 정보를 제공합니다.
Memory Networks는 외부 지식을 메모리 형태로 저장하고, 질문에 따라 메모리에서 관련 정보를 검색하여 답변 생성에 활용합니다. 그러나 외부 지식을 효과적으로 활용하는 것은 여전히 어려운 과제입니다. 지식 베이스의 불완전성, 질문과의 관련성 판단, 추론 과정의 복잡성 등 해결해야 할 문제가 많습니다.
VQA 연구는 딥러닝 DNA에 중요한 유전자를 추가했습니다. CNN-RNN 결합은 이미지와 텍스트를 결합하는 기본적인 틀을 이미지 캡셔닝과 공유합니다. 멀티모달 어텐션은 이미지와 질문 간의 복잡한 관계를 모델링하는 능력을 딥러닝 모델에 부여했습니다. 이는 딥러닝 모델이 단순히 정보를 결합하는 것을 넘어, 정보 간의 상호작용을 이해하고 추론하는 능력을 갖추게 했음을 의미합니다.
외부 지식 통합은 딥러닝 모델이 외부 지식을 활용하여 더 높은 수준의 추론을 수행할 수 있는 가능성을 열었습니다. 이는 딥러닝 모델이 단순히 데이터에만 의존하는 것이 아니라, 인간의 지식과 경험을 활용할 수 있음을 보여줍니다.
10.2.1절과 10.2.2절에서 살펴본 이미지 캡셔닝과 VQA는 초기 멀티모달 딥러닝 연구의 중요한 두 축이었습니다. 이들 연구는 CNN, RNN, 어텐션 메커니즘 등 딥러닝의 핵심 기술을 멀티모달 문제에 적용하고 발전시키는 데 크게 기여했으며, 이후 트랜스포머 기반의 더욱 강력한 멀티모달 모델(CLIP, DALL-E, GPT-4V, Gemini 등)이 등장하는 데 중요한 발판이 되었습니다.
최근에는 ViLT(Vision-and-Language Transformer)와 같은 트랜스포머 기반 VQA 모델이 등장하여 좋은 성능을 보이고 있습니다. ViLT는 이미지 패치와 텍스트 토큰을 동일한 트랜스포머 모델에 입력하여, 이미지와 텍스트 간의 복잡한 상호작용을 효과적으로 모델링합니다.
ViLT(Vision-and-Language Transformer)는 대표적인 트랜스포머 기반 VQA 모델 중 하나입니다. ViLT는 이미지 패치와 텍스트 토큰을 동일한 트랜스포머 모델에 입력하여, 이미지와 텍스트 간의 복잡한 상호작용을 효과적으로 모델링합니다.
다음은 Hugging Face Transformers 라이브러리를 사용하여 ViLT 모델로 VQA를 수행하는 예제 코드입니다.
from transformers import ViltProcessor, ViltForQuestionAnswering
from PIL import Image
import requests
import matplotlib.pyplot as plt
# 모델과 프로세서 로드
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
model = ViltForQuestionAnswering.from_pretrained("dandelin/vilt-b32-finetuned-vqa")
# 이미지 다운로드
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# 이미지 출력
plt.imshow(image)
plt.axis('off') # 축 제거
plt.show()
# 질문 설정
question = "How many cats are in the image?"
print("Question:", question)
# 입력 전처리
encoding = processor(image, question, return_tensors="pt")
# 추론
outputs = model(**encoding)
logits = outputs.logits
idx = logits.argmax(-1).item()
print("Predicted answer:", model.config.id2label[idx])
Question: How many cats are in the image?
Predicted answer: 2이미지와 텍스트 두가지 정보가 있다고 합시다. 이 두가지 정보를 어떻게 결합할까요? 가장 간단한 방법은 이미지 벡터 뒤에 텍스트 벡터를 연이어서 덧붙여 새로운 벡터를 만드는 것입니다. 이질적인 데이터 소스로부터 정보를 연결하는 것을 융합(Fusion)이라 합니다. 이질적인 두 데이터 특성으로부터 효율적으로 정보를 융합하는 것은 멀티모달의 핵심입니다. 멀티모달 딥러닝을 시작하기 어려운 이유 중 하나는 매우 빠르게 발전하는 분야라 체계적인 정리가 부족하기 때문입니다.
이 절에서는 카네기 멜론 대학교(CMU) Multimodal Machine Learning 강의에서 제시하는 방식을 기반으로 멀티모달 융합을 세 가지 주요 범주로 나누어 설명하겠습니다. 이러한 분류는 현재 멀티모달 연구의 표준적인 분류는 아니지만, 다양한 융합 기법을 체계적으로 이해하는 데 매우 유용합니다.
Joint Representations는 여러 모달리티의 데이터를 하나의 공통된 벡터 공간(vector space)에 표현하는 방식입니다. 마치 텍스트와 이미지를 하나의 캔버스에 함께 그려 넣는 것과 같습니다.
각 모달리티의 데이터를 별도로 처리하는 대신, 하나의 통합된 특징 벡터(feature vector)로 융합합니다. 이 벡터는 모달리티의 정보를 포함해 담게 됩니다. 이를 통해 모델은 각 모달리티 간의 깊은 상관관계를 학습할 수 있습니다. 하나의 모델로 여러 모달리티를 처리할 수 있습니다. 또한 여러 모달리티의 정보를 하나의 벡터에 압축하여 표현하므로 모델 구조가 비교적 간단하고 효율적입니다. 그러나 각 모달리티의 고유한 특징이 융합 과정에서 희석되거나 손실될 수 있습니다. 특정 모달리티가 다른 모달리티보다 훨씬 더 많은 정보를 가진 경우, 정보 불균형 문제가 발생할 수 있습니다. 그리고 서로 다른 모달리티의 데이터를 하나의 의미 있는 벡터로 융합하는 것은 매우 어려운 문제입니다.
가장 단순한 방법으로 각 모달리티의 특징 벡터를 단순히 이어 붙이는(concatenate) 방식이 있습니다. 이 외에도 Multi-modal Factorization Model(MFM)은 여러 양상 데이터를 행렬 분해를 통해 결합하여 공통의 표현 공간을 생성합니다. Multi-modal Discriminative Binary Embedding(MDBE)는 이미지와 텍스트 같은 멀티모달 데이터를 이진 코드로 표현해 내는 방법입니다.
최근 연구에서는 COSA(Concatenated Sample)와 같은 방법이 제안되었는데, 이는 여러 이미지-텍스트 쌍을 순차적으로 연결하고 트랜스포머 기반 모델을 적용하여 시각적 콘텐츠와 시간적 단서를 공동으로 학습합니다. 또한 Attentional Concatenation은 텍스트에서 고해상도 이미지를 생성하기 위한 방법으로, 다중 레벨 계단식 구조를 사용하고 이전 레이어의 결과와 단어 벡터를 다음 레이어의 입력으로 활용합니다.
구조 예시
다음은 3가지 방식(Concatenation, MFM, MDBF)의 융합을 도식화 한 것입니다.
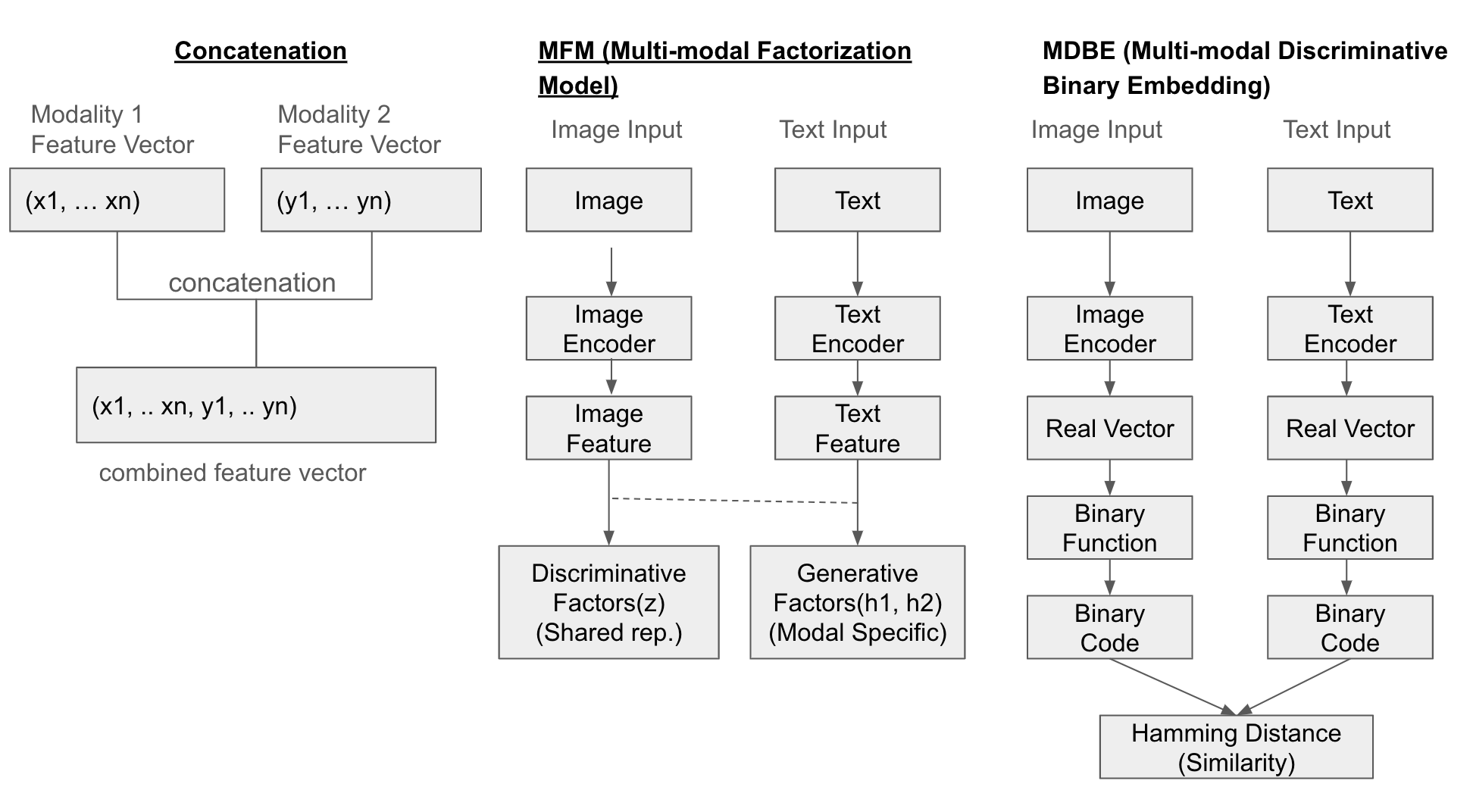
예제
from transformers import AutoModel, AutoProcessor, AutoTokenizer
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# Load pre-trained models and processor/tokenizer for image and text
image_model_name = "google/vit-base-patch16-224-in21k" # ViT (Vision Transformer)
text_model_name = "bert-base-uncased" # BERT
image_processor = AutoProcessor.from_pretrained(image_model_name)
image_model = AutoModel.from_pretrained(image_model_name)
tokenizer = AutoTokenizer.from_pretrained(text_model_name)
text_model = AutoModel.from_pretrained(text_model_name)
# Example image and text
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# Display the image
plt.imshow(image)
plt.axis('off') # Remove axes
plt.show()
# Preprocess image and text
image_inputs = image_processor(images=image, return_tensors="pt")
text_inputs = tokenizer(text, return_tensors="pt")
# Feature extraction (embeddings) for each modality
with torch.no_grad(): # Disable gradient calculation (inference mode)
image_features = image_model(**image_inputs).last_hidden_state[:, 0, :] # [CLS] token embedding
text_features = text_model(**text_inputs).last_hidden_state[:, 0, :] # [CLS] token embedding
# Create Joint Representation (Concatenation)
joint_representation = torch.cat((image_features, text_features), dim=1)
print("Image Features Shape:", image_features.shape) # Image feature vector size
print("Text Features Shape:", text_features.shape) # Text feature vector size
print("Joint Representation Shape:", joint_representation.shape) # Combined feature vector size (image + text)Fast image processor class <class 'transformers.models.vit.image_processing_vit_fast.ViTImageProcessorFast'> is available for this model. Using slow image processor class. To use the fast image processor class set `use_fast=True`.
Image Features Shape: torch.Size([1, 768])
Text Features Shape: torch.Size([1, 768])
Joint Representation Shape: torch.Size([1, 1536])Coordinated Representations는 각 모달리티를 별도의 공간에 표현하되, 이들 간의 관계를 명시적으로 학습하는 방식입니다. 여러 개의 캔버스 그림을 각 캔버스가 서로 조화를 이루도록 하는 것과 같습니다.
각 모달리티를 별도의 특징 벡터로 표현하지만, 이 벡터들이 서로 “협력(coordinate)”하도록 학습합니다. 즉, 각 모달리티의 특징 공간은 독립적이지만, 이들 간의 유사성, 순서 관계 등을 학습하여 서로 의미 있는 관계를 맺도록 합니다. 이 방식의 장점은 각 모달리티의 고유한 특징을 최대한 보존하면서도, 다른 모달리티와의 관련성을 고려할 수 있다는 점입니다. 또한 다양한 형태의 모달리티 간 관계를 학습할 수 있어, 다양한 멀티모달 문제에 적용 가능합니다.
그러나 각 모달리티를 별도로 처리해야 하므로, 모델 구조가 Joint Representations보다 복잡해질 수 있습니다. 이는 모델 설계 및 훈련을 더 어렵게 만들 수 있습니다. 또한 각 모달리티 간의 관계를 명시적으로 학습하는 것은 쉽지 않은 문제입니다.
대표적인 예로 CLIP(Contrastive Language-Image Pre-training)이 있습니다. CLIP은 이미지와 텍스트를 각각 별도의 인코더로 처리하여 특징 벡터를 얻고, 이들 간의 유사도를 학습합니다. CLIP은 이미지와 텍스트가 서로 “짝”을 이루도록 학습하여, 이미지와 텍스트 간의 의미 있는 관계를 파악합니다.
CLIP의 성공은 zero-shot 학습 능력에서 특히 두드러집니다. 사전 학습된 CLIP 모델은 특정 태스크에 대한 추가 학습 없이도 새로운 이미지를 분류하거나 검색할 수 있습니다. 이는 텍스트와 이미지 간의 의미적 연결을 효과적으로 학습했기 때문에 가능한 것입니다.
구조 예시
다음은 CLIP의 융합을 도식화 한 것입니다.
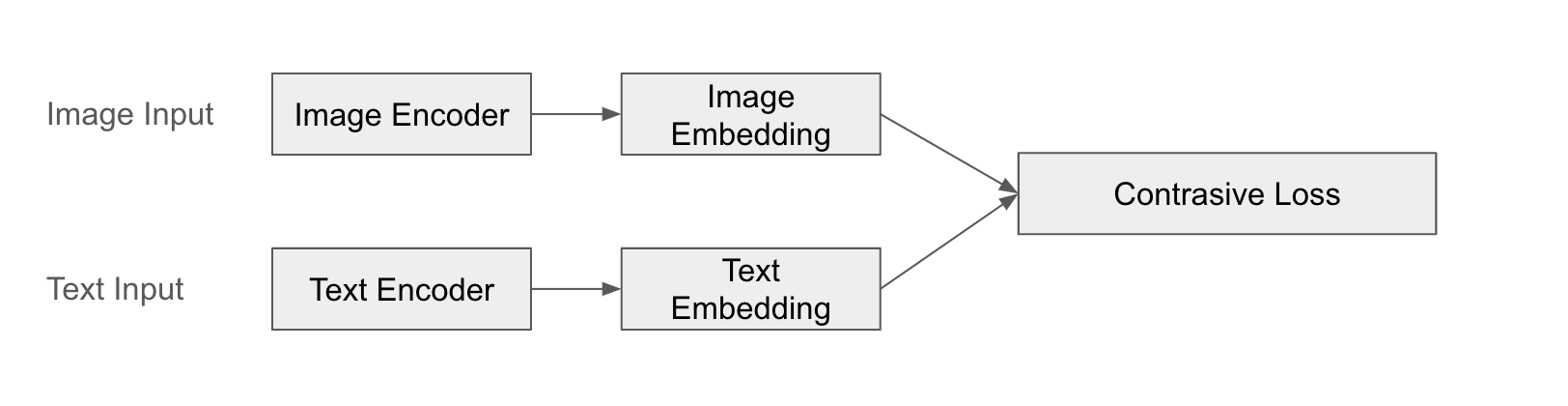
예제
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# Load CLIP model and processor
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
# Example image and text
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# Display image
plt.imshow(image)
plt.axis('off') # Remove axes
plt.show()
# Preprocess image and text
inputs = processor(text=[text], images=image, return_tensors="pt", padding=True)
# Extract image and text features (embeddings)
with torch.no_grad():
outputs = model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
# Coordinated Representation: Keep features of each modality separate
print("Image Features Shape:", image_features.shape)
print("Text Features Shape:", text_features.shape)
# Calculate similarity between image and text (dot product)
similarity = torch.matmul(image_features, text_features.T) # Or text_features @ image_features.T
print("Image-Text Similarity:", similarity.item())
Image Features Shape: torch.Size([1, 512])
Text Features Shape: torch.Size([1, 512])
Image-Text Similarity: 0.29803216457366943위 방식을 응용하면 다음과 같이 간단한 제로샷 테스트가 가능합니다.
# Zero-shot 이미지 분류
# - 여러 텍스트 후보군을 만들고, 각 텍스트와 이미지 간의 유사도를 계산하여 가장 높은 유사도를 갖는 텍스트를 선택
candidate_texts = ["a photo of a cat", "a photo of a dog", "a photo of a bird"]
inputs = processor(text=candidate_texts, images=image, return_tensors="pt", padding=True)
with torch.no_grad():
outputs = model(**inputs)
image_features = outputs.image_embeds
text_features = outputs.text_embeds
logits_per_image = outputs.logits_per_image # 유사도 점수
probs = logits_per_image.softmax(dim=1) # 확률
predicted_class_idx = probs.argmax().item()
predicted_class = candidate_texts[predicted_class_idx]
print("Predicted Class:", predicted_class)
print("Probabilities:", probs)Predicted Class: a photo of a cat
Probabilities: tensor([[9.9403e-01, 5.1377e-03, 8.3070e-04]])Encoder-Decoder는 한 모달리티의 데이터를 다른 모달리티의 데이터로 변환하는 방식입니다. 통상 언어 번역에서 흔히 사용하는 기법입니다.
이 구조에서 인코더(Encoder)는 입력 모달리티(예: 이미지)의 데이터를 특징 벡터로 변환합니다. 이 특징 벡터는 입력 데이터의 핵심 정보를 압축적으로 표현합니다. 디코더(Decoder)는 인코더가 생성한 특징 벡터를 바탕으로 다른 모달리티의 데이터(예: 텍스트)를 생성합니다. 디코더는 인코더의 출력을 “해석”하여 새로운 형태의 데이터를 만들어냅니다. 또한 어텐션 메커니즘을 통해 디코더가 출력 데이터를 생성할 때, 인코더의 특징 벡터 중 어떤 부분에 “주목”해야 하는지를 학습합니다.
이 방식의 장점은 이미지 캡셔닝, VQA, 기계 번역 등 서로 다른 형태의 데이터를 연결하는 다양한 task에 적용할 수 있다는 점입니다. 또한 입력과 출력 모달리티가 달라도 적용 가능하며, 텍스트-이미지, 이미지-텍스트, 오디오-텍스트 등 다양한 조합이 가능합니다.
대표적인 예로는 이미지 캡셔닝과 VQA(Visual Question Answering)가 있습니다. 이미지 캡셔닝은 이미지를 인코더로 처리하여 특징 벡터를 얻고, 디코더를 사용하여 캡션(텍스트)을 생성합니다. VQA는 이미지와 질문(텍스트)을 각각 인코더로 처리하고, 어텐션 메커니즘을 사용하여 이미지와 질문 간의 관련성을 파악한 후, 디코더를 사용하여 답변(텍스트)을 생성합니다.
그러나 입력 또는 출력 데이터가 길어질 경우, 정보 손실이 발생하거나 계산량이 증가할 수 있습니다. 특히 RNN 기반 모델의 경우, 기울기 소실 문제(gradient vanishing problem)로 인해 장거리 의존성 학습이 어려울 수 있습니다. 또한 인코더와 디코더를 동시에 학습해야 하므로, 학습이 불안정하거나 어려울 수 있습니다.
구조 예시
다음은 인코더-디코더 융합을 도식화 한 것입니다.
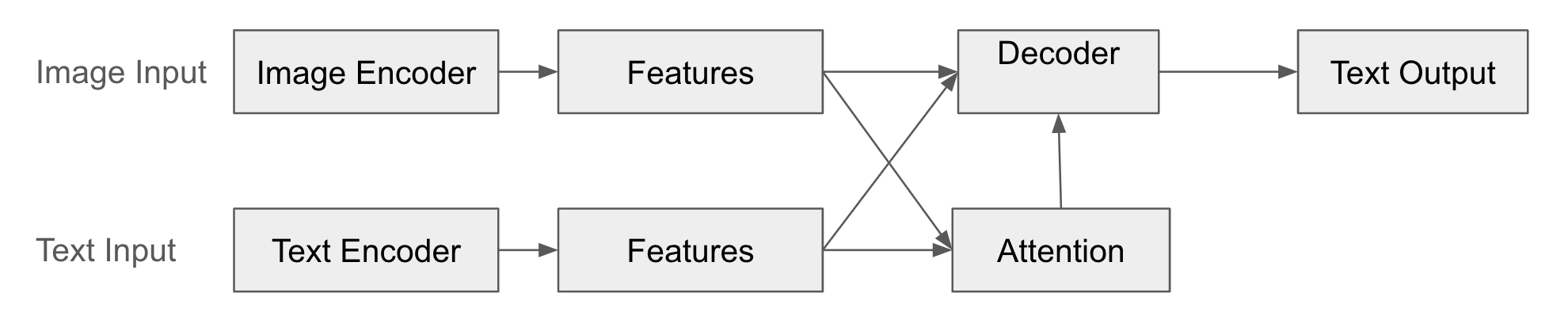
예제
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import requests
import matplotlib.pyplot as plt
# Load model and processor
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
# Download image
url = "http://images.cocodataset.org/val2017/000000000139.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# Display image
plt.imshow(image)
plt.axis('off')
plt.show()
# Input text (optional - Conditional Generation)
# text = "describe this image:" # Prompt (guide image description)
text = "a photo of"
# Preprocess image and text (optional)
# If text is provided, it uses the text as a prompt to generate the caption.
inputs = processor(image, text=text, return_tensors="pt")
# Generate caption
outputs = model.generate(**inputs)
# Decode and print caption
caption = processor.decode(outputs[0], skip_special_tokens=True)
print("Generated caption:", caption)
Generated caption: a photo of a living room with a television and a fireplace이 예제는 Encoder-Decoder 구조의 대표적인 예시인 이미지 캡셔닝을 보여줍니다. 인코더는 이미지(BLIP의 visual encoder)를 입력받아 특징 벡터를 추출합니다. 디코더는 텍스트(BLIP의 text decoder)를 생성합니다. 어텐션 메커니즘을 통해 이미지 특징 벡터의 어느 부분에 주목할지 결정하면서 캡션을 생성합니다. text로 생성되는 캡션에 영향을 주는 prompt를 지정할 수 있습니다. BLIP은 이미지와 텍스트를 모두 입력으로 사용가능하지만 여기서는 이미지만 입력으로 사용하고 텍스트는 디코더에서 생성합니다.
10.3.1, 10.3.2, 10.3.3절에서는 멀티모달 융합의 세 가지 핵심 이론인 Joint Representations, Coordinated Representations, Encoder-Decoder를 살펴보았습니다. 각 방식은 고유의 특징과 장단점을 가지고 있으므로 응용 분야에 따라 적절한 방식을 선택하는 것이 중요합니다.
멀티모달 딥러닝에서 “융합(Fusion)”은 서로 다른 모달리티의 정보를 결합하여 더 풍부하고 강력한 표현을 만드는 핵심 과정입니다. 10.3절에서 CMU 강의 기반의 융합 이론을 간략히 살펴보았지만, 실제 멀티모달 융합 연구는 훨씬 더 다양하고 역동적으로 발전해 왔습니다. 이 딥다이브에서는 융합의 다양한 분류 체계와 최신 연구 동향을 심층적으로 분석하고, 2025년 현재 어떤 기술들이 주목받고 있는지 살펴보겠습니다.
멀티모달 융합은 하나의 기준으로만 분류하기 어렵습니다. 연구자들은 다양한 관점에서 융합 방식을 분류하고 있으며, 각 분류는 서로 배타적이지 않고 상호 보완적입니다.
이 분류는 멀티모달 딥러닝 모델의 “어느 단계”에서 융합이 일어나는지에 초점을 맞춥니다. (본문 10.3.4절 참조)
Early Fusion (초기 융합): 각 모달리티의 “raw” 데이터(또는 매우 초기에 처리된 특징)를 모델의 입력 단계에서 결합합니다.
Late Fusion (후기 융합): 각 모달리티를 별도의 모델로 처리하고, 마지막 단계에서 각 모델의 출력(예: 예측 결과)을 결합합니다.
Hybrid Fusion (혼합 융합): Early Fusion과 Late Fusion을 결합한 방식입니다. 모델의 여러 단계에서 융합을 수행하여, 다양한 수준의 정보를 활용합니다.
Model-Agnostic Fusion: 특정 모델에 의존하지 않는 일반적인 융합 기법 (Early, Late, Hybrid Fusion 등).
Model-Specific Fusion: 특정 모델 구조에 특화된 융합 기법.
트랜스포머의 Cross-Modal Attention: (10.4.2절에서 상세히 설명)
최신 연구: 2025년 6월 11일-12일에 개최 예정인 CVPR 워크샵(MULA 2025)에서는 자율주행 분야에서 다양한 센서 데이터(카메라, LiDAR, 레이더 등)를 효과적으로 융합하기 위한 모델 구조에 대한 연구가 논의될 예정입니다. 이 워크샵은 컴퓨터 비전, 멀티미디어, 원격 감지, 로봇공학 커뮤니티 간의 학제 간 상호작용과 협력을 장려하는 것을 목표로 하며, 특히 자율주행 분야에서의 멀티모달 접근 방식에 큰 관심이 집중되고 있습니다.
대칭적(Symmetric) vs. 비대칭적(Asymmetric) 융합:
대칭적: 모든 모달리티를 동등하게 취급합니다.
비대칭적: 특정 모달리티에 더 큰 비중을 두거나, 다른 역할을 부여합니다.
최신 연구: “Learning Deep Multimodal Feature Representation with Asymmetric Multi-layer Fusion”은 단일 네트워크 내에서 다중 레이어에서 멀티모달 특징을 융합하는 효과적인 프레임워크를 제안했습니다. 이 연구는 채널 셔플과 픽셀 시프트라는 두 가지 비대칭 융합 연산을 도입하여 다양한 융합 방향에 따라 서로 다른 특징을 학습합니다. 또한 2025년 1월 발표된 “Multimodal sentiment analysis based on multi-layer feature fusion”은 모달 불균형과 암묵적 표현 조건에서 정확한 감정 분석을 위한 새로운 접근법을 제시했습니다.
명시적(Explicit) vs. 암시적(Implicit) 융합:
명시적: 모달리티 간의 관계를 명시적으로 정의하거나 모델링합니다. (예: 어텐션 메커니즘)
암시적: 모달리티 간의 관계를 직접 정의하지 않고, 모델이 학습을 통해 스스로 관계를 파악하도록 합니다. (예: 단순 결합)
최신 연구: HCI International 2025 컨퍼런스(25년 6월)에서는 명시적 융합과 암시적 융합의 장단점을 비교하는 연구가 발표될 예정입니다.
2024-2025년 연구에서 가장 주목받는 융합 방식은 어텐션 기반 메커니즘입니다.
개념: 한 모달리티의 특징을 쿼리(query)로 사용하여 다른 모달리티의 특징(key-value)에 어텐션을 적용합니다. (10.4.2절 참조) 이를 통해, 모델은 한 모달리티의 특정 요소가 다른 모달리티의 어떤 요소와 관련이 있는지 세밀하게 파악할 수 있습니다.
장점: 모달리티 간의 세밀하고 유연한 관계를 포착할 수 있습니다. 예를 들어, 이미지 캡셔닝에서 “뛰고 있는”이라는 단어를 생성할 때 이미지 속 개의 “뛰는” 동작에 해당하는 영역에 집중할 수 있습니다.
최신 연구
2025년 1월 발표된 “Bi-Att3DDet” 연구에서는 자율주행을 위한 3D 객체 탐지에 양방향 어텐션 기반 융합 방식을 도입했습니다. 이 연구는 LiDAR와 카메라 데이터 간의 상호보완적 정보를 최대한 활용하기 위해 양방향 상호작용 방식을 제안했습니다.
2024년 3월에 발표되고 2025년 2월에 개정된 “LANMSFF” 연구에서는 다중 시점 얼굴 표정 인식을 위해 경량 어텐션 기반 네트워크와 다중 스케일 특징 융합을 결합했습니다. 이 접근법은 채널 및 공간 어텐션 맵을 동시에 생성하여 중요한 특징을 강조하고 관련 없는 특징을 억제합니다.
최근 신경과학 연구(2025년)에서는 교차 모달 일치성(cross-modal congruency)이 감각 정보의 처리와 축적에 미치는 영향을 조사했습니다. 이 연구는 청각 및 시각적 자극 간의 일치성이 감각 처리의 초기 단계에서 중요한 역할을 한다는 것을 보여주었습니다.
개념: 여러 개의 어텐션 헤드(head)를 사용하여 다양한 관점에서 모달리티 간 관계를 포착합니다. 각 헤드는 서로 다른 가중치 행렬(W_Q, W_K, W_V)을 사용하여 입력 데이터를 변환하고 어텐션을 계산하므로, 각 헤드는 입력 데이터의 서로 다른 측면(예: 의미, 문법 구조, 스타일)에 집중할 수 있습니다.
장점: 다양한 유형의 관계를 동시에 모델링할 수 있어, 더 풍부하고 복잡한 표현을 학습할 수 있습니다. 예를 들어, 이미지와 텍스트를 융합할 때, 어떤 헤드는 이미지 속 객체와 텍스트 속 단어 간의 관계에, 다른 헤드는 이미지의 전반적인 분위기와 텍스트의 어조 간의 관계에 집중할 수 있습니다.
최신 연구: 최근 대규모 멀티모달 모델(LMM)들은 이 기법을 더욱 확장하고 정교화하여, 이미지, 텍스트, 오디오, 비디오 등 다양한 모달리티 간의 복잡한 상호작용을 효과적으로 모델링하고 있습니다.
대조 학습(Contrastive Learning):
개념: 관련된 모달리티 쌍(예: 이미지와 해당 캡션)은 임베딩 공간에서 가깝게, 관련 없는 쌍은 멀리 위치하도록 학습합니다.
장점: 레이블이 없는 대규모 데이터셋에서도 효과적으로 학습할 수 있어, 데이터 부족 문제를 해결하는 데 도움이 됩니다.
최신 연구: “Dual-Level Cross-Modal Contrastive Clustering”(2024)은 시각적 표현과 텍스트 의미 간의 간극을 메우기 위한 새로운 대조 학습 방법 제안합니다.
마스킹 기반 학습(Masking-based Learning):
개념: 입력의 일부를 마스킹하고 이를 다른 모달리티의 정보를 활용하여 복원하도록 학습합니다.
장점: 모달리티 간의 상호 보완적 관계를 학습할 수 있습니다. 예를 들어, 이미지의 일부를 가리고 텍스트 설명을 통해 가려진 부분을 예측하거나, 텍스트의 일부 단어를 가리고 이미지를 통해 가려진 단어를 예측하는 방식으로 학습할 수 있습니다.
최신 연구: CAST(2025)는 Masked Node Prediction(MNP) 사전 학습 전략을 통해 그래프 구조 노드와 텍스트 토큰 간의 정렬을 개선했습니다.
토큰 레벨 융합(Token-level Fusion): 각 모달리티의 개별 토큰(이미지 패치, 텍스트 토큰 등) 간의 세밀한 상호작용을 모델링합니다.
장점: 더 정교한 모달리티 간 관계 포착이 가능합니다. 예를 들어, 이미지 속 특정 객체와 텍스트 속 특정 단어 간의 직접적인 대응 관계를 학습할 수 있습니다.
최신 연구: CAST(2025)는 재료 과학 분야에서 그래프 노드와 텍스트 토큰 간의 토큰 레벨 융합이 인스턴스 레벨 융합보다 우수한 성능을 보인다는 것을 입증했습니다.
인스턴스 레벨 융합(Instance-level Fusion): 각 모달리티의 전체 인스턴스(이미지 전체, 텍스트 전체 등)를 하나의 단위로 취급하여 융합합니다.
장점: 계산 효율성이 높고 구현이 간단합니다.
단점: 모달리티 내부의 세부적인 관계를 포착하지 못할 수 있습니다.
멀티모달 융합은 다양한 방식으로 분류될 수 있으며, 각 분류 방식은 서로 다른 관점을 제공합니다. 실제 연구에서는 이러한 분류들을 조합하여 사용하는 경우가 많습니다.
2025년 현재, 멀티모달 융합 연구는 토큰 레벨의 세밀한 상호작용, 크로스 어텐션 메커니즘, 자기지도 학습 방법을 활용한 효율적인 융합 기법 개발에 초점을 맞추고 있습니다. 특히 CVPR 2025 워크샵(25년 6월, 내슈빌)과 같은 주요 학술 행사에서는 자율주행, 의료 진단, 재료 과학 등 다양한 응용 분야에서의 멀티모달 융합 기술 발전이 활발히 논의될 예정입니다.
이 딥다이브를 통해 멀티모달 융합의 다양한 분류 체계를 이해하고, 각 방식의 특징을 파악함으로써, 앞으로 소개될 다양한 멀티모달 모델들을 더 깊이 있게 분석할 수 있을 것입니다.
10.3.1절부터 10.3.3절까지 우리는 멀티모달 데이터를 융합하는 방법을 살펴보았습니다. 이것은 이론저인 분류입니다. 실제 멀티모달 모델을 설계할 때는 주어진 문제와 데이터의 특성에 맞춰 어떤 융합 방식을, 어느 시점에, 어떻게 적용할지를 전략적으로 결정해야 합니다. 이 절에서는 최신 멀티모달 모델들이 채택하고 있는 정교한 모달리티 통합 전략들을 살펴보겠습니다.
초기 융합은 여러 모달리티의 입력을 모델의 초기 단계에서 결합합니다. 가장 단순한 형태는 각 모달리티의 특징 벡터를 이어 붙이는(concatenate) 방식입니다. 초기 융합의 장점은 모달리티 간의 저수준(low-level) 상호작용을 포착하기 용이하다는 점입니다. 예를 들어, 이미지의 색상과 텍스트의 특정 단어가 강하게 연관되어 있다면, 초기 융합을 통해 이러한 관계를 쉽게 학습할 수 있습니다. 그러나 각 모달리티의 특성을 충분히 활용하지 못할 수 있다는 단점이 있습니다. 특히, 각 모달리티에 특화된 처리가 필요한 경우(예: 이미지에는 CNN, 텍스트에는 RNN), 초기 융합은 비효율적일 수 있습니다.
최근 연구에서는 단순 결합 외에도, 불확실성이 높은 멀티모달 데이터(noisy data) 환경에서 초기 융합의 효과를 검증하는 벤치마크가 제시되었습니다.
초기 융합의 간단한 예를 살펴보겠습니다. Joint Representation 중 concatenation을 사용해서 초기 융합하는 에입니다. 동일한 코드가 사용됩니다. 마지막에 간단한 선형 분류기로 고양이가 있는지 없는지를 판단합니다.
from transformers import AutoModel, AutoProcessor, AutoTokenizer
from PIL import Image
import torch
import requests
import matplotlib.pyplot as plt
# 이미지와 텍스트를 위한 사전 학습된 모델 및 프로세서/토크나이저 로드
image_model_name = "google/vit-base-patch16-224-in21k" # ViT (Vision Transformer)
text_model_name = "bert-base-uncased" # BERT
image_processor = AutoProcessor.from_pretrained(image_model_name)
image_model = AutoModel.from_pretrained(image_model_name)
tokenizer = AutoTokenizer.from_pretrained(text_model_name)
text_model = AutoModel.from_pretrained(text_model_name)
# 예제 이미지 및 텍스트
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
text = "Two cats sleeping on a couch."
# 이미지 출력
plt.imshow(image)
plt.axis('off') # 축 제거
plt.show()
# 이미지와 텍스트 전처리
image_inputs = image_processor(images=image, return_tensors="pt")
text_inputs = tokenizer(text, return_tensors="pt")
# 각 모달리티에 대한 특징 추출 (임베딩)
with torch.no_grad(): # 기울기 계산 비활성화 (추론 모드)
image_features = image_model(**image_inputs).last_hidden_state[:, 0, :] # [CLS] 토큰 임베딩
text_features = text_model(**text_inputs).last_hidden_state[:, 0, :] # [CLS] 토큰 임베딩
# Joint Representation 생성 (Concatenation)
joint_representation = torch.cat((image_features, text_features), dim=1)
print("Image Features Shape:", image_features.shape) # 이미지 특징 벡터 크기
print("Text Features Shape:", text_features.shape) # 텍스트 특징 벡터 크기
print("Joint Representation Shape:", joint_representation.shape) # 결합된 특징 벡터 크기 (image + text)
# Joint Representation을 활용한 추가 작업 (예: 분류)
num_labels = 2 # 예: "고양이 없음(0)" "고양이 있음(1)", 두 가지 클래스로 분류
classifier = torch.nn.Linear(joint_representation.size(1), num_labels) # 간단한 선형 분류기
outputs = classifier(joint_representation)
print("Classification Outputs:", outputs)Fast image processor class <class 'transformers.models.vit.image_processing_vit_fast.ViTImageProcessorFast'> is available for this model. Using slow image processor class. To use the fast image processor class set `use_fast=True`.
Image Features Shape: torch.Size([1, 768])
Text Features Shape: torch.Size([1, 768])
Joint Representation Shape: torch.Size([1, 1536])
Classification Outputs: tensor([[0.1817, 0.0355]], grad_fn=<AddmmBackward0>)위 예에서 이미지와 텍스트가 각각 ViT와 BERT라는 별도의 모델의 출력을 바로 결합합니다. 이미지 특성과 텍스트 특성을 결합하기 전 이 두 벡터에 대해 추가적인 처리(어텐션, 복잡한 변환 등)를 하지 않습니다. 따라서 이는 초기 융합에 해당합니다.
후기 융합은 각 모달리티를 별도의 모델로 처리하고, 마지막 단계에서 각 모델의 출력(예: 예측 결과)을 결합합니다. 이 방식의 장점은 각 모달리티에 특화된 모델을 사용할 수 있다는 점입니다. 예를 들어, 이미지에는 사전 학습된(pre-trained) CNN을, 텍스트에는 사전 학습된 Transformer를 사용하여 각 모달리티의 복잡한 특징을 효과적으로 추출할 수 있습니다. 그러나 모달리티 간의 고수준(high-level) 상호작용만 고려하며, 중간 단계에서의 정보 교환이 어렵다는 단점이 있습니다.
후기 융합은 앙상블(ensemble) 기법과 유사하게, 서로 다른 모달리티별 모델의 출력을 결합하여 성능을 향상시키는 연구가 활발합니다.
혼합 융합은 Early Fusion과 Late Fusion을 결합한 방식입니다. 모델의 여러 단계에서 융합을 수행하여, 다양한 수준의 정보를 활용합니다. 이 방식의 장점은 Early Fusion과 Late Fusion의 장점을 모두 취할 수 있다는 점입니다. 즉, 모달리티 간의 저수준 상호작용과 고수준 상호작용을 모두 고려할 수 있습니다. 그러나 모델 구조가 복잡해지고, 튜닝해야 할 하이퍼파라미터가 많아진다는 단점이 있습니다.
혼합 융합의 대표적인 예로 Cross-Modal Attention이 있습니다. 이는 한 모달리티의 특징을 쿼리(query)로 사용하여 다른 모달리티의 특징(key-value)에 어텐션을 적용하는 방식입니다. 이는 중간 단계에서 융합을 수행하는 대표적인 방법입니다.
최근 연구에서는 attention 외에도, gated mechanism, bilinear pooling 등 다양한 방식으로 중간 단계 융합을 시도하고 있습니다.
2023년 이후, Gemini, GPT-4V와 같은 최신 대규모 멀티모달 모델(LMM)들은 더욱 정교한 모달리티 통합 전략을 도입하여 성능을 크게 향상시켰습니다.
선택적 퓨전 메커니즘 (Selective Fusion Mechanism) 은 각 모달리티의 중요도를 동적으로 판단하여 선택적으로 정보를 통합합니다. 예를 들어, 이미지에 텍스트가 포함된 경우, 텍스트 영역의 시각적 특징과 텍스트 내용을 더 강하게 연관시킵니다. 이는 사람이 상황에 따라 시각 정보와 텍스트 정보의 중요도를 조절하며 이해하는 것과 유사합니다.
동적 가중치 할당 (Dynamic Weighting) 은 태스크와 입력의 특성에 따라 각 모달리티의 기여도를 자동으로 조절합니다. 예를 들어, 시각적 질의응답(VQA) 태스크에서 질문의 성격에 따라 이미지와 텍스트 정보의 가중치를 다르게 할당합니다. “이미지의 색상은 무엇인가요?”라는 질문에는 시각 정보에, “이미지가 의미하는 바는 무엇인가요?”라는 질문에는 텍스트 정보에 더 높은 가중치를 부여합니다.
태스크 특화 통합 방식 (Task-Specific Fusion) 은 특정 태스크의 요구사항에 맞춰 모달리티 통합 방식을 최적화합니다. 이미지 캡셔닝에서는 시각 정보에서 텍스트로의 단방향 변환(one-way transfer)에 중점을 두고, 시각 질의응답에서는 양방향 정보 교환(two-way interaction)을 강화합니다.
이러한 정교한 통합 전략들은 멀티모달 모델의 성능을 크게 향상시켰습니다. 특히, 단순한 정보 결합을 넘어, 각 모달리티의 역할과 중요도를 동적으로 조절하고, 태스크의 특성에 맞춰 융합 방식을 최적화함으로써, 복잡한 추론이 필요한 태스크에서 뛰어난 성과를 보여주고 있습니다.
이러한 통합 전략들은 대규모 데이터셋과 계산 자원을 필요로 하므로, 학습용 예제를 통해 직접 구현하고 실험하기는 어렵습니다. 대신, 각 모델의 논문과 기술 문서를 통해 개념적 이해를 하는 것이 바람직합니다.
10.3절에서는 멀티모달 데이터를 융합하는 다양한 이론적 방법과 전략을 살펴보았습니다. 이를 바탕으로 실제 멀티모달 모델이 어떻게 각 모달리티의 정보를 효과적으로 표현하고, 서로 다른 모달리티 간의 관계를 학습하는지 구체적인 기법들을 살펴보겠습니다. 전체 구현은 chapter_10/multimodal_embeding.py 입니다.
멀티모달 학습의 핵심 과제 중 하나는 서로 다른 특성을 가진 모달리티들을 어떻게 의미 있는 공통 공간에 표현할 것인가 하는 문제입니다. 이미지는 픽셀 값의 2D 배열, 텍스트는 토큰의 1D 시퀀스, 오디오는 시간에 따른 진폭 값 등 각 모달리티는 고유한 표현 방식을 가집니다. 이러한 이질적인 데이터를 효과적으로 처리하기 위해서는 각 모달리티의 본질적인 특성은 유지하면서도, 서로 간의 의미적 관계를 포착할 수 있는 표현 학습 기법이 필요합니다.
초기 접근 방식: 개별 인코더 + 투영(Projection)
초기 멀티모달 모델들은 각 모달리티에 특화된 인코더(예: 이미지에는 CNN, 텍스트에는 RNN)를 사용하여 특징 벡터를 추출한 후, 선형 변환(linear transformation) 또는 얕은 MLP(Multi-Layer Perceptron)를 통해 이들을 공통 차원의 벡터 공간으로 투영(project)하는 방식을 사용했습니다. (10.3.1절의 Joint Representation, Concatenation 방식 참고)
최근 접근 방식: 의미적 정렬 (Semantic Alignment)
최근에는 단순한 차원 맞추기를 넘어, 각 모달리티의 특징 벡터들이 의미적으로 서로 “정렬(align)”되도록 학습하는 방식이 주를 이룹니다. 즉, 관련된 이미지와 텍스트는 임베딩 공간에서 가깝게, 관련 없는 이미지와 텍스트는 멀리 위치하도록 학습하는 것이죠.
Contrastive Learning: (10.3.2절의 Coordinated Representation, CLIP 예시 참고) 이미지-텍스트 쌍을 “positive” 샘플로, 무작위로 섞은 이미지-텍스트 쌍을 “negative” 샘플로 간주하고, positive 샘플 간의 유사도는 높이고, negative 샘플 간의 유사도는 낮추는 방식으로 학습합니다.
Triplet Loss: 이미지 앵커(anchor), positive 텍스트(해당 이미지의 캡션), negative 텍스트(다른 이미지의 캡션)의 세 요소를 사용하여, 앵커 이미지와 positive 텍스트 간 거리는 가깝게, 앵커 이미지와 negative 텍스트 간 거리는 멀게 학습합니다.
구현 예(Contrastive Learning)
class MultimodalEmbedding(nn.Module):
def __init__(self, embedding_dim=512):
super().__init__()
self.image_encoder = models.resnet18(pretrained=True)
self.image_encoder.fc = nn.Sequential(
nn.Linear(512, embedding_dim),
nn.LayerNorm(embedding_dim)
)
self.text_encoder = BertModel.from_pretrained('bert-base-uncased')
self.text_projection = nn.Sequential(
nn.Linear(768, embedding_dim), # BERT output dimension is 768
nn.LayerNorm(embedding_dim)
)
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
def encode_image(self, image):
return self.image_encoder(image)
def encode_text(self, input_ids, attention_mask):
text_features = self.text_encoder(input_ids, attention_mask)[0][:, 0, :] # [CLS] token, keep batch dim
return self.text_projection(text_features)MultimodalEmbedding 클래스:
image_encoder: ResNet18을 사용하여 이미지를 embedding_dim 크기의 특징 벡터로 변환합니다.text_encoder: BERT 모델을 사용하여 텍스트를 특징 벡터로 변환하고, text_projection 레이어를 통해 embedding_dim 크기로 맞춰줍니다.logit_scale: CLIP에서 사용된 학습 가능한 temperature 파라미터입니다.의미적 정렬 메커니즘
의미적 정렬은 크게 다음 두 가지 부분에서 구현됩니다. MultimodalEmbedding 클래스의 forward 메서드와 constrasive_loss()입니다.
def forward(self, image, input_ids, attention_mask):
image_features = self.encode_image(image)
text_features = self.encode_text(input_ids, attention_mask)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits = logit_scale * image_features @ text_features.transpose(-1, -2)
# print("logits:", logits.shape)
return logits # Return a single valueforward 메서드:
encode_image와 encode_text를 사용하여 이미지와 텍스트를 각각 인코딩합니다.
특징 정규화 (Feature Normalization): L2 정규화(L2 normalization)를 통해 image_features와 text_features 벡터의 크기를 1로 만듭니다. 이는 벡터의 방향(direction)만을 고려하여 유사도를 계산하기 위함입니다.
온도 스케일링 (Temperature Scaling): logit_scale을 사용하여 유사도 점수의 분포를 조절합니다. logit_scale을 지수 함수에 적용하여 스케일 값을 얻고, 이를 이미지 특징 행렬과 전치된 텍스트 특징 행렬의 행렬 곱셈에 곱합니다. 행렬 곱셈은 각 이미지 특징 벡터와 모든 텍스트 특징 벡터 간의 내적(dot product)을 계산하여 유사도 점수를 생성합니다.
logits: 이미지 특징 벡터와 텍스트 특징 벡터 간의 유사도 (내적)를 계산합니다. text_features.t() 대신 text_features.transpose(-1, -2)를 사용하여 전치(transpose)를 수행합니다. 텍스트 특징 행렬의 마지막 두 차원을 바꿔 (배치, 텍스트 특징 차원)을 (배치, 특징 차원, 텍스트) 형태로 만들어, (배치, 이미지 특징 차원) 형태의 이미지 특징 행렬과 곱셈이 가능하도록 합니다.
def contrastive_loss(logits): # removed enhanced_similarity
labels = torch.arange(logits.size(0), device=logits.device) # Use logits.size(0)
# Image-to-text and text-to-image contrastive loss
img_txt_loss = nn.CrossEntropyLoss()(logits, labels)
txt_img_loss = nn.CrossEntropyLoss()(logits.T, labels)
# Average loss
return (img_txt_loss + txt_img_loss) / 2contrastive_loss 함수에서는 labels를 logits 행렬의 크기에 맞춰 0부터 (배치 크기 - 1)까지의 정수로 생성합니다. logits 행렬에서 대각선 요소 (i, i)는 i번째 이미지와 i번째 텍스트 간의 유사도를 나타냅니다. 즉, 이미지와 텍스트가 서로 대응되는 쌍(positive pair)의 유사도를 나타내므로, 이 대각선 요소들이 정답이 되도록 labels를 설정합니다. 또한, img_txt_loss는 이미지에서 텍스트로의 유사도에 대한 손실(image-to-text loss)을, txt_img_loss는 텍스트에서 이미지로의 유사도에 대한 손실(text-to-image loss)을 계산합니다. 이 두 손실을 평균냄으로써 양방향(image-to-text, text-to-image)에서의 의미적 정렬을 모두 고려하게 됩니다.
의미적 정렬 메커니즘은 서로 다른 모달리티의 특징들을 의미적으로 일관된 공간에 매핑합니다. 먼저 L2 정규화를 통해 모든 특징 벡터를 단위 구면에 투영하여 모달리티 간의 스케일 차이를 제거합니다. 온도 스케일링 파라미터를 도입하여 유사도 값의 분포를 조절합니다. 높은 온도는 더 부드러운 분포를, 낮은 온도는 더 날카로운 분포를 생성해서 학습의 안정성을 높입니다. 또한 대조 학습을 통해 관련된 이미지-텍스트 쌍은 임베딩 공간에서 가깝게, 무관한 쌍은 멀게 위치하도록 학습됩니다. 특히 이미지에서 텍스트, 텍스트에서 이미지로의 매핑을 동시에 최적화하여 양방향 의미적 정렬을 달성합니다.
CLIP의 대조 학습처럼 관련된 콘텐츠는 가깝게, 무관한 콘텐츠는 멀게 위치하도록 학습합니다. 이러한 대조 학습 기반의 의미적 정렬 전략은 2021년 OpenAI의 CLIP을 시작으로, Google의 PaLM-E, Anthropic의 Claude, 그리고 DeepMind의 Gemini에 이르기까지 발전했습니다. 초기 CLIP이 이미지-텍스트 쌍의 단순 대조 학습에 집중했다면, 최신 모델들은 다중 모달리티 간의 상호 관계를 더욱 정교하게 포착합니다. 특히 Gemini는 이미지, 텍스트, 오디오, 비디오 등 다양한 모달리티 간의 의미적 정렬을 동시에 학습하며, 각 모달리티의 고유한 특성을 보존하면서 통합된 의미 공간을 구축합니다.
예제 실행
훈련에 사용하는 데이터는 flicker8k를 사용합니다. train_multimodal_embedding 함수를 사용하여 EnhancedMultimodalEmbedding (또는 EnhancedMultimodalEmbedding_no_p) 모델을 Flickr8k 데이터셋으로 훈련할 수 있습니다. main 함수에서 모델, 데이터 로더, optimizer 등을 설정하고, train_multimodal_embedding 함수를 호출하면 훈련이 시작됩니다.
# download flickr8k.
!mkdir data;cd data;wget "https://github.com/awsaf49/flickr-dataset/releases/download/v1.0/flickr8k.zip";unzip -q flickr8k.zip -d ./flickr8kmkdir: cannot create directory ‘data’: File exists
--2025-03-09 16:33:12-- https://github.com/awsaf49/flickr-dataset/releases/download/v1.0/flickr8k.zip
Resolving github.com (github.com)... 20.200.245.247
Connecting to github.com (github.com)|20.200.245.247|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://objects.githubusercontent.com/github-production-release-asset-2e65be/753516996/d7c62b13-1e50-40ea-8fae-f34a44b1695f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=releaseassetproduction%2F20250309%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20250309T073156Z&X-Amz-Expires=300&X-Amz-Signature=ff62cf7df8ac3deba8bd6f4f775e164abf03c6d2d6d86d740e5407e52702c6a3&X-Amz-SignedHeaders=host&response-content-disposition=attachment%3B%20filename%3Dflickr8k.zip&response-content-type=application%2Foctet-stream [following]
--2025-03-09 16:33:12-- https://objects.githubusercontent.com/github-production-release-asset-2e65be/753516996/d7c62b13-1e50-40ea-8fae-f34a44b1695f?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=releaseassetproduction%2F20250309%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20250309T073156Z&X-Amz-Expires=300&X-Amz-Signature=ff62cf7df8ac3deba8bd6f4f775e164abf03c6d2d6d86d740e5407e52702c6a3&X-Amz-SignedHeaders=host&response-content-disposition=attachment%3B%20filename%3Dflickr8k.zip&response-content-type=application%2Foctet-stream
Resolving objects.githubusercontent.com (objects.githubusercontent.com)... 185.199.109.133, 185.199.111.133, 185.199.110.133, ...
Connecting to objects.githubusercontent.com (objects.githubusercontent.com)|185.199.109.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 1112971163 (1.0G) [application/octet-stream]
Saving to: ‘flickr8k.zip’
flickr8k.zip 100%[===================>] 1.04G 56.8MB/s in 19s
2025-03-09 16:33:32 (56.9 MB/s) - ‘flickr8k.zip’ saved [1112971163/1112971163]
import torch
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader
# Assuming dldna.chapter_10.multimodal_embedding is in the same directory or Python path.
# Adjust if necessary (e.g., from multimodal_embedding import ...).
from dldna.chapter_10.multimodal_embedding import Flickr8kDataset, MultimodalEmbedding, train_multimodal_embedding, generate_example
# Data transformation setup
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Dataset and DataLoader setup
image_dir = './data/flickr8k/Images' # Replace with the actual path to your image directory
caption_file = './data/flickr8k/captions.txt' # Replace with the actual path to your caption file
dataset = Flickr8kDataset(image_dir, caption_file, transform=transform)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4)
# Model initialization
model = MultimodalEmbedding()
# Model training
train_multimodal_embedding(model, train_loader, val_loader, num_epochs=3)
# Model saving
torch.save(model.state_dict(), 'multimodal_embedding_model.pth')
# Example generation
model_path = 'multimodal_embedding_model.pth'
generate_example(model_path, image_dir, caption_file)Epoch 1/3: 15%|█▍ | 147/1012 [00:16<01:36, 8.96it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 1/3: 100%|██████████| 1012/1012 [01:53<00:00, 8.90it/s]Epoch 1/3 - Train Loss: 0.9618Epoch 1/3 - Validation Loss: 0.5212
Epoch 1: Saved best model with Validation Loss = 0.5212Epoch 2/3: 52%|█████▏ | 525/1012 [00:59<00:55, 8.84it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 2/3: 100%|██████████| 1012/1012 [01:54<00:00, 8.83it/s]Epoch 2/3 - Train Loss: 0.3393Epoch 2/3 - Validation Loss: 0.4240
Epoch 2: Saved best model with Validation Loss = 0.4240Epoch 3/3: 34%|███▍ | 347/1012 [00:39<01:15, 8.85it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 3/3: 100%|██████████| 1012/1012 [01:54<00:00, 8.83it/s]Epoch 3/3 - Train Loss: 0.2313Epoch 3/3 - Validation Loss: 0.3891
Epoch 3: Saved best model with Validation Loss = 0.3891
Image 0:
Top 3 Captions (Image -> Text):
- football players in red congratulate each other as crowds in red cheer behind. (prob: 0.9970)
- a man in black holds up an obama 08 sign. (prob: 0.0023)
- a large group of bicycles racing on the street (prob: 0.0004)
Caption: football players in red congratulate each other as crowds in red cheer behind.
Top 3 Images (Text -> Image):
- Image 0 (prob: 0.9983)
- Image 17 (prob: 0.0013)
- Image 2 (prob: 0.0001)
크로스모달 어텐션은 서로 다른 모달리티 간의 관계를 효과적으로 모델링하기 위한 사용됩니다. 이는 ViT의 셀프 어텐션을 확장하여 이미지와 텍스트 같은 이질적인 데이터 간의 상호작용이 가능하게 합니다.
모달리티 간 어텐션 설계
크로스모달 어텐션은 각 모달리티의 특성을 고려한 비대칭 구조를 가집니다.
class CrossModalAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.image_proj = nn.Linear(config.image_dim, config.hidden_dim)
self.text_proj = nn.Linear(config.text_dim, config.hidden_dim)
self.attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
def forward(self, image_features, text_features):
image_proj = self.image_proj(image_features)
text_proj = self.text_proj(text_features)
attn_output, _ = self.attention(text_proj, image_proj, image_proj)
return attn_output이미지와 텍스트 특징을 공통의 잠재 공간으로 투영한 후, 멀티헤드 어텐션 메커니즘을 통해 두 모달리티 간의 관계를 학습합니다. 텍스트 특징이 쿼리로, 이미지 특징이 키와 값으로 사용되어 텍스트가 이미지의 관련 부분에 주의를 기울이도록 합니다.
비대칭 어텐션 패턴
각 모달리티의 고유한 특성을 보존하면서도 효과적인 정보 교환을 위해 비대칭 어텐션 패턴을 사용합니다.
class HierarchicalCrossModalAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.local_image_attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
self.local_text_attention = nn.MultiheadAttention(config.hidden_dim, config.num_heads)
self.image_to_text_attention = CrossModalAttention(config)
self.text_to_image_attention = CrossModalAttention(config)
self.output_layer = nn.Linear(config.hidden_dim * 2, config.hidden_dim)
def forward(self, image_features, text_features):
local_image = self.local_image_attention(image_features, image_features, image_features)[0]
local_text = self.local_text_attention(text_features, text_features, text_features)[0]
image_attended_text = self.image_to_text_attention(image_features, local_text)
text_attended_image = self.text_to_image_attention(text_features, local_image)
combined_features = torch.cat([image_attended_text, text_attended_image], dim=-1)
output = self.output_layer(combined_features)
return output여기서는 이미지에서 텍스트, 텍스트에서 이미지로의 양방향 어텐션을 별도로 수행합니다. 이를 통해 각 모달리티가 상대 모달리티의 관련 정보에 선택적으로 집중할 수 있게 됩니다.
계층적 어텐션 구조
복잡한 멀티모달 관계를 포착하기 위해 여러 층의 어텐션을 계층적으로 구성합니다. 하위 층에서는 각 모달리티 내의 지역적 특징을 처리하고, 상위 층에서는 모달리티 간의 전역적 관계를 모델링합니다. 이러한 계층적 구조는 GPT-4V와 Gemini와 같은 모델에서 핵심적인 역할을 합니다.
class EnhancedMultimodalEmbedding_no_p(MultimodalEmbedding):
def forward(self, image, input_ids, attention_mask):
image_features = self.encode_image(image)
text_features = self.encode_text(input_ids, attention_mask)
image_features = self.image_preserve(image_features)
text_features = self.text_preserve(text_features)
combined_features = self.cross_modal_attention(image_features, text_features)
combined_features = combined_features / combined_features.norm(dim=-1, keepdim=True)
logit_scale = self.logit_scale.exp()
logits = logit_scale * combined_features @ combined_features.t()
return logitsimport torch
from torchvision import models, transforms
from torch.utils.data import Dataset, DataLoader
from collections import namedtuple
from dldna.chapter_10.crossmodal_attention import Flickr8kDataset, CrossModalEmbedding, train_crossmodal_embedding, generate_example
# Configuration
config = namedtuple('Config', ['embedding_dim', 'image_dim', 'text_dim', 'hidden_dim', 'num_heads'])(
embedding_dim=512, # Output embedding dimension
image_dim=512, # ResNet18 image encoder output dimension
text_dim=512, # Text feature (768 from BERT -> 512 after projection)
hidden_dim=512, # Cross-modal attention internal hidden dimension
num_heads=8 # Number of multi-head attention heads
)
# Data transformation setup
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# Dataset and DataLoader setup
image_dir = './data/flickr8k/Images' # Change to the actual path
caption_file = './data/flickr8k/captions.txt' # Change to the actual path
dataset = Flickr8kDataset(image_dir, caption_file, transform=transform)
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4, pin_memory=True)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4, pin_memory=True)
# Model initialization
model = CrossModalEmbedding(config)
# Model training
train_crossmodal_embedding(model, train_loader, val_loader, num_epochs=3)
# Model saving
torch.save(model.state_dict(), 'crossmodal_embedding_model.pth')Epoch 1/3: 4%|▍ | 40/1012 [00:04<01:41, 9.53it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 1/3: 100%|██████████| 1012/1012 [01:47<00:00, 9.41it/s]Epoch 1/3 - Train Loss: 0.9663Epoch 1/3 - Validation Loss: 0.5378Epoch 2/3: 58%|█████▊ | 582/1012 [01:02<00:45, 9.36it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 2/3: 100%|██████████| 1012/1012 [01:48<00:00, 9.31it/s]Epoch 2/3 - Train Loss: 0.3381Epoch 2/3 - Validation Loss: 0.4452Epoch 3/3: 0%| | 4/1012 [00:00<02:27, 6.82it/s]Image file not found: ./data/flickr8k/Images/imageEpoch 3/3: 100%|██████████| 1012/1012 [01:48<00:00, 9.35it/s]Epoch 3/3 - Train Loss: 0.2288Epoch 3/3 - Validation Loss: 0.3743# Example generation
model_path = 'crossmodal_embedding_model.pth'
generate_example(model_path, image_dir, caption_file)Image 0:
Top 3 Captions (Image -> Text):
- two people walk out onto the desert sand. (prob: 0.9862)
- a man takes a picture of him and his friend with his phone. (prob: 0.0092)
- the little boy wearing the blue shirt is putting dirt in his mouth. (prob: 0.0013)
Caption: two people walk out onto the desert sand.
Top 3 Images (Text -> Image):
- Image 0 (prob: 0.9898)
- Image 2 (prob: 0.0089)
- Image 4 (prob: 0.0005)
Perceiver는 2021년 DeepMind가 제안한 멀티모달 아키텍처입니다. 기존 트랜스포머의 이차 복잡도 문제(입력 시퀀스 길이에 따라 계산량이 제곱으로 증가)를 해결하면서도 다양한 모달리티(이미지, 텍스트, 오디오, 포인트 클라우드 등)를 효과적으로 처리할 수 있는 구조를 제시했습니다. Perceiver는 특히 입력 데이터의 크기가 매우 큰 경우(예: 고해상도 이미지, 긴 텍스트)에 유리합니다. 여기서는 전체적인 아키텍처 설명을 하고 예제는 생략하였습니다. 코드는 설명을 위한 예시 코드입니다.
Perceiver의 핵심 아이디어
Perceiver는 다음과 같은 아이디어를 기반으로 합니다.
Perceiver는 입력 시퀀스의 길이에 관계없이 고정된 크기의 잠재 벡터(latent array) 를 사용합니다. 이 잠재 벡터는 입력 데이터의 정보를 압축하여 표현하는 역할을 하며, 마치 병목처럼 많은 양의 입력 정보를 적은 수의 잠재 벡터로 요약합니다. 따라서 입력 데이터의 크기가 아무리 크더라도(예: 10,000개의 토큰) 잠재 벡터의 수는 고정(예: 256개)되기 때문에 계산 복잡도와 메모리 사용량을 크게 줄일 수 있습니다.
class Perceiver(nn.Module):
def __init__(self, ..., num_latents=256, latent_dim=512, ...):
super().__init__()
# Latent vector initialization (key!)
self.latents = nn.Parameter(torch.randn(num_latents, latent_dim))
# ...위 코드에서 self.latents가 바로 그 잠재 벡터를 나타냅니다. nn.Parameter로 정의되어 학습 가능한 파라미터입니다.
Perceiver는 입력 모달리티(이미지, 텍스트, 오디오 등)에 특화된 처리 방식(예: CNN, RNN)을 사용하지 않습니다. 대신, 각 모달리티는 간단한 전처리(예: 이미지 패치, 텍스트 토큰화)를 거쳐 공통된 형태(sequence of vectors)로 변환됩니다. 이후에는 모달리티 종류와 무관하게 동일한 트랜스포머 기반 아키텍처(Cross-Attention, Self-Attention)를 사용하여 처리합니다. 이를 통해 다양한 모달리티를 유연하게 처리할 수 있고, 새로운 모달리티를 추가하기도 쉽습니다.
Perceiver는 여러 층의 셀프 어텐션(self-attention) 을 사용하여 잠재 벡터들을 점진적으로 업데이트합니다. 각 층에서 잠재 벡터들은 서로 정보를 교환하며, 입력 데이터의 복잡한 패턴을 학습합니다. 초기에는 단순한 특징을 나타내던 잠재 벡터들이, 여러 층을 거치면서 점차 추상적이고 고수준의 의미를 표현하게 됩니다.
Perceiver의 작동 방식 (간략화된 코드 예시)
import torch
import torch.nn as nn
class Perceiver(nn.Module):
def __init__(self,
input_channels=3, # Input channels (e.g., RGB image)
input_axis=2, # Input dimension (image=2, video=3)
num_latents=256, # Number of latent vectors
latent_dim=512, # Latent vector dimension
num_heads=8, # Number of attention heads
depth=6): # Model depth (number of self-attention layers)
super().__init__()
# 1. Latent vector initialization (key!)
self.latents = nn.Parameter(torch.randn(num_latents, latent_dim))
# 2. Input projection (matches input dimension to latent dimension)
self.input_proj = nn.Linear(input_dim, latent_dim)
# 3. Cross-Attention (learns relationships between input and latent vectors)
# self.cross_attention = nn.MultiheadAttention(latent_dim, num_heads, batch_first=True)
# 4. Self-Attention (learns relationships between latent vectors) - repeated multiple times
self.self_attention_layers = nn.ModuleList([
nn.MultiheadAttention(latent_dim, num_heads, batch_first=True)
for _ in range(depth)
])
def forward(self, x): # x: Input data (image, text, ...)
batch_size = x.shape[0]
# 1. Input projection
x = self.input_proj(x)
# 2. Latent vector replication (for each item in the batch)
latents = self.latents.unsqueeze(0).expand(batch_size, -1, -1) # (B, num_latents, latent_dim)
# 3. (Optional) Cross-attention (between input and latent vectors)
# latents, _ = self.cross_attention(latents, x, x) # query, key, value
# 4. Self-attention (between latent vectors) - repeated multiple times
for layer in self.self_attention_layers:
latents, _ = layer(latents, latents, latents) # query, key, value
return latents # Return the processed latent vectorsPerceiver의 장단점
Perceiver는 입력 크기에 관계없이 계산 복잡도가 거의 일정하다는 효율성을 가지며, 다양한 모달리티를 동일한 방식으로 처리할 수 있는 유연성을 제공합니다. 또한, 새로운 모달리티를 쉽게 추가할 수 있는 확장성도 Perceiver의 장점입니다. 하지만 Perceiver는 여전히 트랜스포머를 기반으로 하기 때문에 구조가 복잡하며, 잠재 벡터의 차원과 층 수가 커지면 모델이 매우 커질 수 있다는 단점이 있습니다. 또한, 이미지 분류와 같이 특정 태스크에서는 CNN과 같이 해당 태스크에 특화된 모델보다 성능이 떨어질 수 있습니다.
Perceiver IO
Perceiver의 후속 연구인 Perceiver IO는 입력뿐만 아니라 출력도 잠재 벡터를 통해 처리하는 방식을 제안했습니다. 이를 통해 다양한 출력 형태(classification, regression, sequence generation 등)를 유연하게 다룰 수 있게 되었습니다. Perceiver IO는 Perceiver보다 더 일반적이고 강력한 모델로 평가받고 있습니다.
여기서는 크로스 어텐션의 기본 구조부터 시작하여 점진적으로 매커니즘을 추가하면서 훈련 가능과 성능을 비교합니다. 이를 통해 멀티모달 학습에서 발생하는 문제들을 이해하고, 이를 해결하기 위한 실용적인 접근 방법을 살펴보겠습니다.
크로스 어텐션 메커니즘을 설계할 때 이 절의 내용과 같이 점진적으로 복잡도를 높여가며 실험하는 방식은 매우 일반적이고 권장되는 접근 방식입니다. 제거 연구(Ablation study) 라고 불리는 이 방식은 각 구성 매커니즘의 중요성을 파악하고, 최종 모델의 성능에 기여하는 핵심 요소를 식별하는 데 효과적입니다. 새로운 아키텍처를 제안하는 많은 논문에서 이러한 접근 방식을 사용합니다. 또한, 단순히 최종 성능만이 아니라 훈련 과정에서의 안정성 문제를 함께 논의하는 것은 실용적인 관점에서 매우 중요합니다.
비교 훈련 방식
실험은 앞서 살펴본 flickr8k 데이터 셋으로 텍스트와 이미지 두개의 인풋을 가지고 상호 유사도를 훈련시킵니다. 훈련에서는 크로스 어텐션이 버전이 정해져 있으며 각 버전별로 복잡도가 증가합니다. 버전별로 크로스 어텐션의 매커니즘을 하나씩 추가하고, 그에 따라 훈련을 진행해서 비교를 합니다. 모든 훈련은 동일한 하이퍼파라미터를 사용합니다. 훈련 에포크는 5로 고정했습니다.
예제의 구조
예제는 다음과 같은 구조로 구성되어 있습니다.
chatper_10/mm
├── cat_resized.png
├── cross_attention
│ ├── v0.py
│ ├── v1.py
│ ├── v2.p
│ ├── v3.py
│ .... (계속 존재)
├── train_multimodal.py
└── evaluate_models.pycross_attention 폴더 밑에 v1부터 v11까지 순차적으로 크로스어텐션의 복잡도를 증가시킵니다. train_mulimodal.py는 하나의 훈련이 끝나뎐 다음 버전의 모델을 동적으로 생성해서 훈련을 지속합니다. 훈련에서는 정확도, 대조 손실, 수행시간등의 메트릭을 저정해서 최종 비교 테이블을 생성합니다. 손실값과 정확도로 훈련 가능 여부를 판단하는 것은 바람직하지 않습니다. 대조학습의 특성상 올바르게 훈련이 진행되었는지 확인하는 가장 쉬운 방법은 기존에 없던 데이터로 평가 하는 방법입니다. 제로샷(zero-shot)으로 모델을 평가하는 파일은 evalute_models.py입니다.
평가하는 이미지는 다음입니다.

평가는 5개의 텍스트와 위 이미지의 유사도를 측정하는 방식으로 이루어집니다.
test_captions = [
"A dog playing in the park",
"A cat sleeping on a couch",
"Children playing soccer",
"A sunset over the ocean",
"A person cooking in the kitchen"
]모델 훈련이 제대로 이루어졌다면 5개 캡션 중 두번째 “A cat sleeping on a couch”이 가장 높은 유사도가 나와야 합니다. 위 이미지는 훈련데이터에 없던 것으로 전형적인 제로샷 테스트에 해당합니다.
크로스어텐션 동적할당
cross_attion의 버전을 바꾸는 것은 동적 할당을 통해서 이루어집니다.
from dldna.chapter_10.mm.cross_attention.v0 import CrossAttention as v0
from dldna.chapter_10.mm.cross_attention.v1 import CrossAttention as v1
# ... (import other versions) ...
from dldna.chapter_10.mm.cross_attention.v11 import CrossAttention as v11
def get_cross_attention(version, config=None):
if config is None:
config = {}
if version == 'v0':
return v0(**config)
elif version == 'v1':
return v1(**config)
# ... (other version conditions) ...
elif version == 'v11':
return v11(**config)
else:
raise ValueError(f"Invalid cross-attention version: {version}")
# ...
class ImageTextMatchingModel(nn.Module):
def __init__(self, image_encoder_dim=2048, text_encoder_dim=768, projection_dim=256):
super().__init__()
self.image_encoder = ImageEncoder(image_encoder_dim, projection_dim)
self.text_encoder = TextEncoder(text_encoder_dim, projection_dim)
# The CrossAttention module is dynamically assigned in main().
self.cross_attention = None # CrossAttention(projection_dim)
def forward(self, image, input_ids, attention_mask):
# ...
image_attended, text_attended = self.cross_attention(
image_features.unsqueeze(1),
text_features.unsqueeze(1)
)
# ...
# ...
def run_training(model_versions, ...):
# ...
for model_version in model_versions:
# ...
# Model initialization
model = ImageTextMatchingModel()
# Dynamically load the CrossAttention module
model.cross_attention = get_cross_attention(model_version, config=config)
# ...이 부분은 실험의 핵심인 다양한 버전의 Cross-Attention 모듈을 동적으로 로드하고 적용하는 로직을 구현합니다. get_cross_attention 함수는 문자열 형태의 버전(v0, v1, …, v11)을 입력받아 해당 버전에 맞는 CrossAttention 클래스의 인스턴스를 반환합니다. run_training 함수 내부에서는 model_versions 리스트에 지정된 각 버전에 대해 ImageTextMatchingModel을 초기화하고, get_cross_attention 함수를 호출하여 model.cross_attention에 해당 버전의 Cross-Attention 모듈을 할당합니다.
이러한 동적 할당 방식은 코드의 재사용성을 높이고, 실험 관리를 용이하게 합니다. 새로운 버전의 Cross-Attention을 추가할 때, get_cross_attention 함수에 해당 버전을 추가하기만 하면 되므로, 훈련 코드를 크게 수정할 필요가 없습니다. 또한 run_training 함수의 model_versions 리스트를 통해 어떤 버전들을 훈련할지 쉽게 제어할 수 있습니다.
Contrastive Loss 계산 및 훈련 루프
def contrastive_loss(logits):
labels = torch.arange(len(logits), device=logits.device)
loss_i = nn.CrossEntropyLoss()(logits, labels)
loss_t = nn.CrossEntropyLoss()(logits.t(), labels)
return (loss_i + loss_t) / 2
def train(model, train_loader, val_loader, epochs=10, lr=1e-4, model_version='v0'):
# ...
for epoch in range(epochs):
model.train()
total_loss = 0
# ...
for batch in tqdm(train_loader, ...):
images, input_ids, attention_mask = [x.to(device) for x in batch]
optimizer.zero_grad()
logits = model(images, input_ids, attention_mask)
loss = contrastive_loss(logits)
loss.backward()
optimizer.step()
total_loss += loss.item()
# ... (validation 및 지표 계산) ...이 부분은 모델의 학습에 사용되는 Contrastive Loss 계산과 훈련 루프를 정의합니다. contrastive_loss 함수는 이미지-텍스트 쌍의 유사도 점수(logits)를 입력받아 Contrastive Loss를 계산합니다. 이때, 정답 레이블은 logits의 대각선 (즉, 동일 인덱스의 이미지-텍스트 쌍)에 해당하는 요소들이 1 (유사함)이고, 나머지는 0 (유사하지 않음)이 되도록 생성됩니다 (torch.arange 사용). 이미지 기준 Cross-Entropy Loss (loss_i)와 텍스트 기준 Cross-Entropy Loss (loss_t)를 모두 계산하고, 이 둘의 평균을 최종 loss로 사용합니다.
훈련 방식 : 매커니즘의 추가
가장 단순한 어텐션 구조에서 하나씩 기능을 추가하면서 테스트를 할 것입니다. 추가되는 기능을 “메커니즘”이라고 부르도록 하겠습니다. 각 메커니즘이 추가되면서 어떤 메커니즘이 멀티모달 어텐션 설계에 영향을 미치는지 살펴보겠습니다. 먼저 훈련 코드를 일부 살펴본 다음 바로 훈련 결과를 보도록 하겠습니다. 그 이후에 각 크로스모달 어텐션에서 어떤 매커니즘이 훈련의 성패를 좌우했는지도 살펴보겠습니다.
다음은 훈련 코드입니다. 훈련을 하면 각 모델이 model_final_{버전}.pth 으로 저장이됩니다. 이 저장된 모델을 이용해서 평가를 수행합니다.
from dldna.chapter_10.mm.train_multimodal import run_training
# model_versions = ['v0', 'v1'] # List of model versions to train
model_versions = ['v0', 'v1', 'v2', 'v3', 'v4', 'v5', 'v6', 'v7', 'v8', 'v9', 'v10_1', 'v10_2', 'v10_3', 'v10_4', 'v10_5', 'v10_6', 'v11']
epochs = 5
lr = 1e-4
# Dataset
image_dir = './data/flickr8k/Images' # Change to the actual path
caption_file = './data/flickr8k/captions.txt' # Change to the actual path
results_df = run_training(model_versions, epochs=epochs, lr=lr, image_dir=image_dir, caption_file=caption_file) # Train multiple versions
# Print results
print("\nTraining Results:")
# Print results in Markdown table format
print(results_df.to_markdown(index=False))모델로 평가를 수행합니다.
from dldna.chapter_10.mm.evaluate_models import evaluate_all_models
# Test captions (fixed)
test_captions = [
"A dog playing in the park",
"A cat sleeping on a couch",
"Children playing soccer",
"A sunset over the ocean",
"A person cooking in the kitchen"
]
# Run model evaluation
image_path = './cat_resized.png'
model_dir = '.'
model_versions = ['v0', 'v1', 'v2', 'v3', 'v4', 'v5', 'v6', 'v7', 'v8', 'v9', 'v10_1', 'v10_2', 'v10_3', 'v10_4', 'v10_5', 'v10_6', 'v11']
results_df = evaluate_all_models(model_dir, image_path, test_captions, model_versions)
# Print results (Markdown table)
print(results_df.to_markdown(index=False))
# Print results (detailed)
for _, row in results_df.iterrows():
print(f"\nModel: {row['model_version']}")
print(f" Best Caption: {row['best_caption']}")
print(f" Trained Well: {row['trained_well']}")
print(f" Similarity Ratio: {row['similarity_ratio']}")
print(f" Similarity Gap: {row['similarity_gap']}")
print(" All Similarities:")
for caption, sim in zip(test_captions, row['all_similarities']):
print(f" - {caption:<30}: {sim}")| model_version | best_caption | all_similarities | similarity_ratio | similarity_gap | trained_well | similarity_ratio_rank |
|---|---|---|---|---|---|---|
| v0 | A cat sleeping on a couch | [‘5.322’, ‘15.477’, ‘-4.509’, ‘-6.609’, ‘2.107’] | 2.908 | 10.155 | True | 1 |
| v1 | A cat sleeping on a couch | [‘3.117’, ‘18.174’, ‘-6.475’, ‘-1.825’, ‘8.705’] | 2.088 | 9.469 | True | 3 |
| v2 | A cat sleeping on a couch | [‘3.085’, ‘12.541’, ‘-4.252’, ‘0.924’, ‘6.849’] | 1.831 | 5.692 | True | 5 |
| v3 | Children playing soccer | [‘34.882’, ‘34.882’, ‘34.882’, ‘34.882’, ‘34.882’] | 1 | 0 | False | 14 |
| v4 | A cat sleeping on a couch | [‘7.385’, ‘8.301’, ‘-1.038’, ‘-6.262’, ‘1.240’] | 1.124 | 0.915 | True | 12 |
| v5 | Children playing soccer | [‘27.357’, ‘27.357’, ‘27.357’, ‘27.357’, ‘27.357’] | 1 | 0 | False | 14 |
| v6 | A cat sleeping on a couch | [‘5.022’, ‘14.861’, ‘-5.370’, ‘-8.630’, ‘9.063’] | 1.64 | 5.798 | True | 7 |
| v7 | A dog playing in the park | [‘16.300’, ‘16.300’, ‘16.300’, ‘16.300’, ‘16.300’] | 1 | 0 | False | 14 |
| v8 | A cat sleeping on a couch | [‘9.841’, ‘15.442’, ‘-7.350’, ‘-1.249’, ‘11.023’] | 1.401 | 4.419 | True | 10 |
| v9 | A cat sleeping on a couch | [‘10.382’, ‘15.192’, ‘-5.582’, ‘-1.594’, ‘5.953’] | 1.463 | 4.81 | True | 9 |
| v10_1 | A dog playing in the park | [‘0.940’, ‘0.472’, ‘-0.554’, ‘0.334’, ‘-0.111’] | 1.991 | 0.468 | False | 4 |
| v10_2 | A cat sleeping on a couch | [‘17.720’, ‘17.720’, ‘17.720’, ‘17.720’, ‘17.720’] | 1 | 0 | True | 14 |
| v10_3 | A cat sleeping on a couch | [‘0.516’, ‘1.479’, ‘-0.941’, ‘-0.106’, ‘0.694’] | 2.132 | 0.786 | True | 2 |
| v10_4 | A cat sleeping on a couch | [‘5.913’, ‘10.334’, ‘-5.989’, ‘-1.024’, ‘5.151’] | 1.748 | 4.421 | True | 6 |
| v10_5 | A cat sleeping on a couch | [‘6.601’, ‘9.990’, ‘-5.984’, ‘-2.988’, ‘-0.070’] | 1.513 | 3.389 | True | 8 |
| v10_6 | A dog playing in the park | [‘33.967’, ‘33.302’, ‘31.580’, ‘32.710’, ‘31.384’] | 1.02 | 0.665 | False | 13 |
| v11 | A cat sleeping on a couch | [‘11.315’, ‘15.491’, ‘-10.428’, ‘-0.004’, ‘10.014’] | 1.369 | 4.175 | True | 11 |
이 실험 결과들을 바탕으로, 각 크로스 어텐션 버전별 훈련 결과를 분석하고, 훈련 성공/실패 원인을 다음과 같이 정리할 수 있습니다.
| 버전 | 어텐션 구조 | 주요 특징 | 훈련 결과 | 상세 설명 |
|---|---|---|---|---|
| v0 | 독립적 양방향 어텐션 | 스케일링된 내적 어텐션만 사용 | 훈련 성공 | 가장 기본적인 구조. 이미지와 텍스트 각각에 대해 독립적으로 어텐션을 계산. 스케일링 외 다른 정규화/변환 없음. 별도의 정규화 과정이 없어, 입력 feature의 scale 변화에 민감. |
| v1 | 공유 어텐션 | 단일 어텐션 행렬과 전치행렬 사용 | 훈련 성공 | 이미지→텍스트, 텍스트→이미지 어텐션 계산에 동일한 어텐션 행렬을 공유. 양방향 정보 교환을 시도했지만, 정규화 부재로 인해 여전히 입력 스케일에 민감하고, 두 모달리티 간의 비대칭적인 관계를 제대로 반영하지 못함. |
| v2 | 공유 어텐션 + LN | 입력에 LayerNorm 적용 | 훈련 성공 | 입력 특징에 LayerNorm을 적용하여 특징 스케일 안정화. v1의 문제점(입력 스케일 민감성)을 해결. 어텐션 행렬은 여전히 공유. |
| v3 | v2 + 잔차 연결 | 출력에 잔차 연결 추가 | 훈련 실패 | 어텐션 계산 후 원본 특징(image_features, text_features)을 직접 더하는 잔차 연결을 추가. 이는 원본 특징을 과도하게 보존하여, 두 모달리티 간의 상호 작용을 통해 새로운 특징을 생성하는 것을 방해. 특히, 얕은 네트워크 구조에서는 이러한 현상이 두드러짐. |
| v4 | v2 + 프로젝션 | 모달리티별 선형 변환 | 훈련 성공 | 각 모달리티에 독립적인 선형 프로젝션(self.image_proj, self.text_proj) 적용. LayerNorm으로 정규화된 입력(image_norm, text_norm)에 대해 별도의 선형 변환을 적용함으로써, 각 모달리티의 특징 공간을 더 유연하게 조절하고, 어텐션 계산에 적합한 형태로 변환. |
| v5 | v2 + 혼합 비율 | 0.5 고정 혼합비율 | 훈련 실패 | 원본 특징(image_norm, text_norm)과 어텐션 출력(image_attended, text_attended)을 고정된 비율(0.5)로 혼합. 잔차 연결(v3)과 유사하게 원본 특징을 보존하지만, 고정된 혼합 비율 때문에 모델이 데이터에 따라 유연하게 가중치를 조절하는 능력을 제한. |
| v6 | 공유 어텐션 + Q/K/V | Q/K/V 변환과 단일 LayerNorm | 훈련 성공 | 입력(image_norm, text_norm)에 대해 Query(Q), Key(K), Value(V)를 생성하는 별도의 선형 변환(self.to_q, self.to_k, self.to_v)을 추가. 이를 통해 어텐션 메커니즘이 더 풍부한 특징 표현을 학습. 여전히 공유 어텐션 행렬을 사용. |
| v7 | 공유 멀티헤드 | 멀티헤드 + 출력 정규화 | 훈련 실패 | 공유 어텐션 행렬을 멀티헤드 어텐션으로 확장. 입력에 대한 LayerNorm은 유지(v2). 각 헤드가 서로 다른 특징을 학습할 수 있도록 했지만, 여전히 공유 어텐션을 사용하기 때문에 이미지→텍스트와 텍스트→이미지 간의 비대칭적인 관계를 제대로 모델링하지 못함. 출력에 LayerNorm을 적용했음에도, 훈련에는 실패. |
| v8 | 독립 멀티헤드 | 독립적 양방향 멀티헤드 + 이중 정규화 | 훈련 성공 | 이미지→텍스트와 텍스트→이미지 어텐션을 독립적인 멀티헤드 어텐션으로 분리. 입력뿐만 아니라 출력에도 LayerNorm 적용. 각 모달리티의 특성을 보존하면서 양방향 정보 교환을 효과적으로 수행. |
| v9 | v8 + Pre-LN + FFN | 게이트된 FFN과 드롭아웃 추가 | 훈련 성공 | v8의 구조에 Pre-LayerNorm, 게이트된 Feed-Forward Network (FFN), 드롭아웃 추가. Pre-LN은 어텐션과 FFN 전에 LayerNorm을 적용하여 훈련 안정성을 높임. 게이트된 FFN은 GELU 활성화 함수와 드롭아웃을 사용하여 비선형성을 강화하고 과적합을 방지. FFN 출력에만 잔차 연결을 적용하여 정보 흐름을 개선. |
| v10_1 | v9 + 모달리티별 Q/K/V | 각 모달리티에 특화된 변환 | 훈련 실패 | v9를 기반으로, 각 모달리티에 대해 별도의 Q, K, V 프로젝션(self.image_to_q, self.image_to_k, …, self.text_to_v)을 사용. 이는 모델의 복잡도를 크게 증가시키지만, 각 모달리티의 특성을 지나치게 분리하여, 두 모달리티 간의 상호 작용을 학습하는 데 어려움을 겪음. |
| v10_2 | v9 + 교차 게이트 | 모달리티 간 정보 흐름 제어 | 훈련 실패 | v9에 교차 게이트 메커니즘 추가. 어텐션 출력과 원본 feature를 concat한 후, gate layer(sigmoid)를 적용해서, modality간 정보 교환을 제어함. 그러나, gate layer에 대한 정규화가 없고, 초기 gate값이 매우 작아(self.gate_scale = 0.1) 정보 흐름을 효과적으로 제어하지 못하고, 학습을 방해. |
| v10_3 | v9 + 컨텍스트 레이어 | 모달리티별 문맥 정보 처리 | 훈련 성공 | v9에 각 모달리티별 컨텍스트 레이어(self.image_context, self.text_context) 추가. 이는 각 모달리티의 특징을 추가적으로 처리하여 어텐션 계산 전에 더 풍부한 문맥 정보를 제공. |
| v10_4 | v9 + 멀티쿼리 | K,V 공유 방식의 어텐션 | 훈련 성공 | v9에서 멀티쿼리 어텐션(Multi-Query Attention) 메커니즘을 도입. Query는 각 헤드별로 독립적으로 유지하되, Key와 Value는 모든 헤드가 공유(self.to_kv). 이는 파라미터 수를 줄이면서도, 각 헤드가 서로 다른 관점에서 쿼리를 생성하여 다양한 특징을 포착. |
| v10_5 | v9 + 계층적 멀티헤드 | 3단계 레벨별 특징 처리, 가중치 기반 융합 | 훈련 성공 | v9에 계층적 멀티헤드 어텐션 구조를 도입. 입력 특징을 3단계 레벨로 나누어 처리(self.level_projections, self.level_norms). 각 레벨에서 독립적인 멀티헤드 어텐션을 수행하고, 학습 가능한 가중치(self.level_weights)를 사용하여 각 레벨의 출력을 융합. 이는 모델이 다양한 수준의 추상화된 특징을 학습하고, 이들을 효과적으로 결합. |
| v10_6 | v9 + 대조학습 멀티헤드 | 대조학습 기반 유사도 제한, 특징 보강 | 훈련 실패 | v9에 대조 학습(contrastive learning)을 위한 별도의 프로젝션 레이어(self.contrast_proj)를 추가. 정규화된 대조 학습 특징 간의 유사도를 계산하고, 이를 원본 특징에 직접 더하는 방식으로 어텐션 출력을 보강. 그러나 이는 원본 feature를 왜곡시켜 v3와 유사하게, 두 modality간 상호작용을 방해해서, 학습에 실패. |
| v11 | v9 + 멀티쿼리 + 계층적 융합 | K,V 공유와 3단계 레벨 특징 처리 결합 | 훈련 성공 | v10_4 (멀티쿼리)와 v10_5 (계층적 멀티헤드)의 장점을 결합. 멀티쿼리 어텐션을 통해 파라미터 효율성을 높이고, 계층적 융합을 통해 다양한 수준의 특징을 통합. v9의 Pre-LN, 게이트 FFN, 드롭아웃 등의 안정화 기법도 유지. |
1. v0: 독립적 양방향 어텐션 - 기본 구조
v0는 가장 기본적인 형태의 Cross-Modal Attention을 구현합니다. 이미지와 텍스트 각각에 대해 독립적인 어텐션을 계산하며, 스케일링된 내적(Scaled Dot-Product Attention) 외에 다른 정규화나 변환은 사용하지 않습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
def forward(self, image_features, text_features):
# Image -> Text attention
attn_i2t = torch.matmul(image_features, text_features.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
image_attended = torch.matmul(attn_i2t, text_features)
# Text -> Image attention
attn_t2i = torch.matmul(text_features, image_features.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
text_attended = torch.matmul(attn_t2i, image_features)
return image_attended, text_attendedv0는 별도의 정규화 과정이 없기 때문에, 입력 특징의 스케일 변화에 민감하게 반응합니다. 입력 데이터의 스케일이 학습 과정에서 크게 변하면, 어텐션 가중치가 불안정해지고, 훈련이 제대로 이루어지지 않을 수 있습니다.
2. v2: 공유 어텐션 + Layer Normalization
v2는 v1에서 입력 특징에 Layer Normalization(LN)을 적용하여 특징 스케일을 안정화시킨 버전입니다. v1은 이미지→텍스트, 텍스트→이미지 어텐션 계산에 동일한 어텐션 행렬(가중치 행렬)과 그 전치 행렬을 사용했지만, 입력 스케일에 민감하다는 단점이 있었습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
# Co-attention + added LN
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
self.norm = nn.LayerNorm(dim) # Use a single LayerNorm
def forward(self, image_features, text_features):
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
# Simple attention calculation
attn = torch.matmul(image_norm, text_norm.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# Bidirectional feature fusion (without residual connection)
image_out = torch.matmul(attn, text_norm)
text_out = torch.matmul(attn.transpose(-2, -1), image_norm)
return image_out, text_outimage_norm = self.norm(image_features) 및 text_norm = self.norm(text_features)에서 입력 특징에 Layer Normalization을 적용합니다. Layer Normalization은 각 샘플(미니배치 내의 각 이미지 또는 텍스트)에 대해 독립적으로 정규화를 수행합니다. 즉, 각 샘플의 특징 벡터의 평균과 분산을 계산하여, 이를 0과 1로 만듭니다. 이를 통해 입력 특징의 스케일이 크게 변하더라도, 어텐션 가중치가 발산하는 것을 방지하여 학습을 안정화합니다.
그러나 여전히 한계는 있습니다. v2는 Layer Normalization을 통해 입력 스케일 문제를 해결했지만 이미지→텍스트와 텍스트→이미지 어텐션에 동일한 어텐션 행렬을 사용합니다. 이는 두 모달리티 간의 비대칭적인 관계를 충분히 반영하지 못할 수 있습니다. 이미지에서 텍스트를 생성하는 것과 텍스트에서 이미지를 생성하는 것은 서로 다른 복잡도를 가질 수 있습니다.이를 동일한 어텐션 메커니즘으로 처리하는 것은 비효율적일 수 있습니다.
3. v3: v2 + 잔차 연결 (Residual Connection) - 실패 사례
ResNet 모델 아키텍처 이후, 전가의 보도 처럼 사용되었던 잔차 연결이 여기서는 실패의 원인이 됩니다. 잔차 연결은 일반적으로 네트워크가 깊어질수록 발생할 수 있는 기울기 소실(Gradient Vanishing) 문제를 완화하고, 더 깊은 네트워크를 효과적으로 학습하기 위해 널리 사용되는 기법입니다. 하지만, 이번 실험에서는 잔차 연결이 오히려 성능을 저하시키는 실패 사례 를 보여주었습니다.
이는 매우 중요한 관찰입니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CrossAttention(nn.Module):
def __init__(self, dim):
super().__init__()
self.scale = dim ** -0.5
self.norm = nn.LayerNorm(dim) # Use a single LayerNorm
def forward(self, image_features, text_features):
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
# Simple attention calculation
attn = torch.matmul(image_norm, text_norm.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# Bidirectional feature fusion
image_attended = torch.matmul(attn, text_norm)
text_attended = torch.matmul(attn.transpose(-2, -1), image_norm)
# Add residual connection
image_out = image_features + image_attended
text_out = text_features + text_attended
return image_out, text_out일반적으로 잔차 연결은 네트워크가 깊어질수록 학습이 어려워지는 문제를 해결하는 데 효과적입니다. 하지만 v3에서는 다음과 같은 이유로 인해 오히려 성능이 저하되는 결과를 초래했습니다.
상대적으로 얕은 네트워크: v3 모델은 깊이가 깊지 않은, 비교적 얕은 네트워크 구조를 가지고 있습니다. 잔차 연결은 깊은 네트워크에서 기울기 소실 문제를 완화하는 데 큰 도움을 주지만, 얕은 네트워크에서는 그 효과가 미미하며, 오히려 정보의 흐름을 방해할 수 있습니다.
원본 특징의 과도한 보존: Cross-Modal Attention의 핵심은 이미지와 텍스트, 두 가지 다른 모달리티(Modality) 간의 상호 작용을 통해 새로운 특징을 생성하는 것입니다. 하지만 v3에서는 어텐션 연산 결과에 원본 특징 벡터를 그대로 더함으로써, 어텐션 메커니즘을 통해 얻은 중요한 정보를 희석시키고, 두 모달리티 간의 상호 작용을 통한 특징 생성을 방해하는 결과를 낳았습니다. 즉, 모델이 새로운 정보를 학습하기보다 기존 정보를 유지하는 데 집중하게 된 것입니다.
v3의 실험 결과는 잔차 연결이 항상 성능을 향상시키는 만능 해결책이 아니라는 중요한 교훈을 줍니다. 잔차 연결은 네트워크의 깊이, 적용 위치, 그리고 문제의 특성 등을 고려하여 신중하게 사용해야 합니다. v3는 잔차 연결을 부적절하게 사용하여 성능이 저하된 대표적인 실패 사례라고 할 수 있습니다.
4. v8: 독립 멀티헤드 어텐션
v8에서는 이전 버전(v7)의 문제점을 해결하고, Cross-Modal Attention의 성능을 향상시키는 중요한 변화를 도입했습니다. 바로 이미지→텍스트 어텐션과 텍스트→이미지 어텐션을 독립적인 멀티헤드 어텐션(Multi-Head Attention)으로 분리한 것입니다. 또한, 입력뿐만 아니라 어텐션 연산의 출력에도 Layer Normalization을 적용하여 훈련의 안정성을 더욱 강화했습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
# v8 - Independent multi-head
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
self.norm = nn.LayerNorm(dim)
# Projections for multi-head attention
self.to_q = nn.Linear(dim, dim)
self.to_k = nn.Linear(dim, dim)
self.to_v = nn.Linear(dim, dim)
# Output projection
self.to_out = nn.Linear(dim, dim)
# Add output normalization
self.out_norm = nn.LayerNorm(dim)
def forward(self, image_features, text_features):
B, N_i, _ = image_features.shape
_, N_t, _ = text_features.shape
H = self.num_heads
# Input normalization
image_norm = self.norm(image_features)
text_norm = self.norm(text_features)
def split_heads(x):
return x.reshape(B, -1, H, self.head_dim).transpose(1, 2)
# Image -> Text direction attention
q_img = split_heads(self.to_q(image_norm))
k_txt = split_heads(self.to_k(text_norm))
v_txt = split_heads(self.to_v(text_norm))
attn_i2t = torch.matmul(q_img, k_txt.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
image_attended = torch.matmul(attn_i2t, v_txt)
# Text -> Image direction attention
q_txt = split_heads(self.to_q(text_norm))
k_img = split_heads(self.to_k(image_norm))
v_img = split_heads(self.to_v(image_norm))
attn_t2i = torch.matmul(q_txt, k_img.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
text_attended = torch.matmul(attn_t2i, v_img)
# Combine heads and output projection
image_attended = image_attended.transpose(1, 2).reshape(B, N_i, -1)
text_attended = text_attended.transpose(1, 2).reshape(B, N_t, -1)
image_out = self.out_norm(self.to_out(image_attended))
text_out = self.out_norm(self.to_out(text_attended))
return image_out, text_outv7에서도 멀티헤드 어텐션을 도입했지만, 여전히 이미지→텍스트와 텍스트→이미지 어텐션에 동일한 Q, K, V 변환을 사용했습니다. 즉, 모든 헤드가 같은 Q, K, V 행렬을 공유했기 때문에, 각 헤드가 서로 다른 특징을 학습하는 데 제약이 있었고, 이는 모델의 표현력을 제한하는 요인이 되었습니다. v8은 이러한 문제를 해결하기 위해 독립적인 Q, K, V 변환을 각 방향(이미지→텍스트, 텍스트→이미지)과 각 헤드에 적용함으로써, 모델이 훨씬 더 유연하고 풍부한 특징 표현을 학습할 수 있도록 했습니다.
5. v9: v8 + Pre-LN + FFN (게이트 FFN + 드롭아웃)
v9는 v8의 구조를 기반으로, 훈련 안정성과 성능을 더욱 향상시키기 위한 세 가지 중요한 메커니즘을 추가했습니다. 바로 Pre-Layer Normalization, 게이트 Feed-Forward Network (FFN), 그리고 드롭아웃(Dropout)입니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
# v9 - Dropout before gated FFN, pass through norm at the end -> trainable
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8, dropout=0.1, ff_dim=None):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.scale = self.head_dim ** -0.5
ff_dim = ff_dim or dim * 4
# Normalization layers for Pre-LN
self.attn_norm = nn.LayerNorm(dim)
self.ff_norm = nn.LayerNorm(dim)
# Projections for multi-head attention
self.to_q = nn.Linear(dim, dim)
self.to_k = nn.Linear(dim, dim)
self.to_v = nn.Linear(dim, dim)
# Output projection
self.to_out = nn.Linear(dim, dim)
# Dropout
self.dropout = nn.Dropout(dropout)
# Gated feedforward network
self.ff_gate = nn.Sequential(
nn.Linear(dim, ff_dim),
nn.GELU(),
nn.Dropout(dropout)
)
self.ff_value = nn.Sequential(
nn.Linear(dim, ff_dim),
nn.GELU(),
nn.Dropout(dropout)
)
self.ff_out = nn.Linear(ff_dim, dim)
def forward(self, image_features, text_features):
B, N_i, _ = image_features.shape
_, N_t, _ = text_features.shape
H = self.num_heads
def split_heads(x):
return x.reshape(B, -1, H, self.head_dim).transpose(1, 2)
# Pre-LN: Normalize before attention
image_norm = self.attn_norm(image_features)
text_norm = self.attn_norm(text_features)
# Image -> Text direction attention
q_img = split_heads(self.to_q(image_norm))
k_txt = split_heads(self.to_k(text_norm))
v_txt = split_heads(self.to_v(text_norm))
attn_i2t = torch.matmul(q_img, k_txt.transpose(-2, -1)) * self.scale
attn_i2t = attn_i2t.softmax(dim=-1)
attn_i2t = self.dropout(attn_i2t) # Apply dropout to attention weights
image_attended = torch.matmul(attn_i2t, v_txt)
# Text -> Image direction attention
q_txt = split_heads(self.to_q(text_norm))
k_img = split_heads(self.to_k(image_norm))
v_img = split_heads(self.to_v(image_norm))
attn_t2i = torch.matmul(q_txt, k_img.transpose(-2, -1)) * self.scale
attn_t2i = attn_t2i.softmax(dim=-1)
attn_t2i = self.dropout(attn_t2i) # Apply dropout to attention weights
text_attended = torch.matmul(attn_t2i, v_img)
# Combine heads and output projection
image_attended = image_attended.transpose(1, 2).reshape(B, N_i, -1)
text_attended = text_attended.transpose(1, 2).reshape(B, N_t, -1)
# Output projection and dropout
image_attended = self.dropout(self.to_out(image_attended))
text_attended = self.dropout(self.to_out(text_attended))
# Residual connection - connecting the original image features makes training impossible.
# image_attended = image_attended + image_features
# text_attended = text_attended + text_features
# Pre-LN: Normalize before FFN
image_ff = self.ff_norm(image_attended)
text_ff = self.ff_norm(text_attended)
# Gated feedforward processing
def apply_ff(x):
gate = self.ff_gate(x)
value = self.ff_value(x)
return self.dropout(self.ff_out(gate * value))
# FFN output and residual connection - this type of residual connection is possible.
image_out = apply_ff(image_ff) + image_attended
text_out = apply_ff(text_ff) + text_attended
return image_out, text_outPre-Layer Normalization: v8에서는 어텐션 연산 이후에 Layer Normalization을 적용했지만(Post-LN), v9에서는 이전에 적용합니다(Pre-LN). self.image_norm_q, self.image_norm_k, …, self.text_norm_v가 여기에 해당합니다. Pre-LN은 Post-LN보다 훈련 안정성이 더 높고, 별도의 warmup이 필요 없다는 장점이 있어 최근 Transformer 기반 모델에서 널리 사용됩니다.
게이트 Feed-Forward Network (FFN): v8의 어텐션 연산 이후에 FFN을 추가하여 비선형성을 강화하고, 모델의 표현력을 높입니다.
self.image_ffn과 self.text_ffn은 FFN을 정의합니다. FFN은 두 개의 선형 레이어(Linear Layer)와 그 사이에 GELU(Gaussian Error Linear Unit) 활성화 함수, 그리고 드롭아웃으로 구성됩니다.self.image_ffn_norm, self.text_ffn_norm)을 적용합니다. v3와 다르게, FFN을 거친 후에 잔차연결을 적용하여, 단순 원본 feature 보존이 아닌, 비선형 처리 이후 정보 결합이 이루어져, 정보 흐름을 개선하고, 성능 향상에 기여합니다.드롭아웃 (Dropout): self.dropout은 어텐션 가중치와 FFN 내부에 적용되는 드롭아웃을 정의합니다. 드롭아웃은 학습 중에 무작위로 뉴런을 비활성화하여 모델의 과적합(Overfitting)을 방지하는 데 효과적인 정규화(Regularization) 기법입니다.
추가된 매커니즘들의 효과
v9는 이러한 기법들의 조합을 통해 Cross-Modal Attention의 성능을 크게 향상시켰으며, 이후 버전들의 기반이 되었습니다.
v0, v1 (기본 구조): 정규화 없이 단순한 어텐션만 사용한 v0, v1은 훈련은 성공 했습니다. 하지만, v1의 경우 훈련은 되었으나, 훈련과 검증 데이터셋 모두에서 “고양이” 관련 캡션에 더 높은 유사도를 보였습니다. 이는 정규화의 중요성을 시사합니다.
v2 (LayerNorm): 입력에 LayerNorm을 적용한 v2는 훈련에 성공했습니다. 이는 입력 특징의 스케일을 안정화하는 것이 중요함을 보여줍니다.
v3 (잔차 연결): v2에 잔차 연결을 추가한 v3는 훈련에 실패했습니다. 이는 멀티모달 학습에서 잔차 연결이 항상 도움이 되는 것은 아님을 보여줍니다. 잔차 연결이 원본 특징을 과도하게 유지하여, 두 모달리티 간의 상호 작용을 학습하는 데 방해가 될 수 있습니다.
v4 (프로젝션): 각 모달리티에 독립적인 선형 변환(projection)을 추가한 v4는 훈련에 성공했습니다. 이는 각 모달리티의 특징 공간을 적절히 변환하는 것이 중요함을 시사합니다.
v7 (공유 멀티헤드): 공유 어텐션 행렬을 멀티헤드로 확장한 v7은 훈련에 실패했습니다. 이는 각 헤드가 서로 다른 모달리티의 특성을 제대로 반영하지 못했기 때문으로 해석됩니다.
v8 (독립 멀티헤드): 각 방향(이미지→텍스트, 텍스트→이미지)에 대해 독립적인 멀티헤드 어텐션을 사용하고, 입력과 출력에 별도의 LayerNorm을 적용한 v8은 훈련에 성공했습니다. 이는 각 모달리티의 특성을 보존하면서 정보 교환을 하는것이 중요함을 보여줍니다.
v10_1 (모달리티별 Q/K/V): v9를 기반으로 각 모달리티에 특화된 Q/K/V 변환을 도입한 v10_1은 훈련이 불안정했습니다. 이는 모델의 복잡도가 증가하고, 과적합의 위험이 커졌기 때문으로 풀이됩니다.
v10_2 (Cross-Gate): v9에 cross-modal gating 메커니즘을 추가한 v10_2는 훈련에 실패했습니다. 이는 gating 메커니즘이 두 모달리티 간의 정보 흐름을 적절히 제어하지 못하고, 오히려 학습을 방해했기 때문으로 보입니다. 너무 이른 단계에서 정보 교환을 제한하는 것이 원인일 수 있습니다.
v10_3 (컨텍스트 레이어): 각 모달리티에 별도의 컨텍스트 처리 레이어를 추가한 v10_3는 훈련에 성공했습니다. 이 레이어는 각 모달리티의 특징을 더 정제하고, 추가적인 문맥 정보를 제공하여 성능 향상에 기여했을 것으로 예상됩니다.
v10_4 (멀티쿼리 어텐션): 쿼리(Q)는 독립적으로 유지하되, 키(K)와 값(V)는 공유하는 멀티쿼리 어텐션을 적용한 v10_4는 훈련에 성공했습니다. 이는 파라미터 수를 줄이면서도 효율적인 정보 교환을 가능하게 하여, 일반화 성능을 향상시킨 것으로 해석됩니다.
v10_5 (계층적 멀티헤드): 3단계의 계층적 구조를 도입하고, 각 레벨에서 독립적인 멀티헤드 어텐션을 적용한 후, 가중치를 통해 융합하는 v10_5는 훈련에 성공했습니다. 이는 점진적으로 특징을 통합하고, 각 레벨의 정보를 효과적으로 활용하여 성능을 높인 것으로 분석됩니다.
v10_6 (대조 학습 멀티헤드): 대조 학습을 위한 별도의 프로젝션 레이어를 추가하고, 원본 특징에 유사도 정보를 직접 더하는 방식으로 훈련한 v10_6은 훈련이 불안정했습니다. 이는 유사도 정보가 원본 특징을 왜곡시켜 학습을 방해했을 가능성이 있습니다.
v11 (멀티쿼리 + 계층적 융합): 멀티쿼리 어텐션(v10_4)과 계층적 멀티헤드(v10_5)의 장점을 결합한 v11은 훈련에 성공했습니다. 이는 파라미터 효율성과 점진적 특징 통합이라는 두 가지 이점을 모두 활용하여 안정적인 학습을 달성했음을 의미합니다.
결론
이 제거 실험을 통해 다음과 같은 결론을 얻을 수 있습니다.
이러한 제거 실험은 멀티모달 학습에서 각 구성 요소의 역할과 중요성을 이해하는 데 매우 유용합니다. 더 나아가 새로운 모델을 설계할 때 중요한 지침을 제공합니다. 특정 메커니즘의 유무에 따른 성능 변화를 체계적으로 분석함으로써, 어떤 요소가 멀티모달 융합에 효과적인지, 그리고 어떤 조합이 최적의 결과를 가져오는지 파악할 수 있습니다.
보다 체계적인 실험 케이스와 프로젝트용 프레임워크를 설계하면 대규모 모델과 다양한 매커니즘에 대한 실험도 원활히 수행할 수 있습니다. 연구에 도움이 되길 바랍니다.
이번 절에서는 이미지 처리 분야에 혁신을 가져온 비전 트랜스포머(Vision Transformer, ViT)와, ViT의 확장인 ViT-22B, MAE를 간단히 살펴보겠습니다.
2020년, 구글 리서치 팀은 “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”이라는 논문을 통해 ViT를 세상에 소개했습니다. ViT는 오랫동안 이미지 처리 분야를 지배해 온 합성곱 신경망(Convolutional Neural Network, CNN)의 시대가 저물고, 트랜스포머(Transformer) 기반의 새로운 시대가 도래했음을 알리는 신호탄이었습니다.
ViT의 핵심 아이디어는 간단합니다. 이미지를 여러 개의 작은 조각(패치, Patch)으로 나누고, 각 패치를 마치 텍스트 문장의 단어(토큰)처럼 취급하는 것입니다. 이렇게 하면 이미지는 일련의 패치 시퀀스(sequence)로 변환되고, 트랜스포머는 이 시퀀스를 입력으로 받아 처리합니다.
ViT는 CNN과 비교하여 다음과 같은 중요한 차이점을 갖습니다.
지역성(Locality) vs. 전역성(Globality): CNN은 컨볼루션 필터를 사용하여 이미지의 지역적인 특징을 추출하는 데 중점을 둡니다. 반면, ViT는 어텐션 메커니즘(Attention Mechanism)을 통해 각 패치가 이미지 전체의 다른 모든 패치와의 관계를 직접적으로 고려할 수 있습니다. 즉, 이미지 전체의 맥락(context)을 파악하는 데 유리합니다.
계층적 구조(Hierarchical Structure) vs. 평탄한 구조(Flat Structure): CNN은 여러 계층의 컨볼루션(convolution)과 풀링(pooling) 연산을 통해 점진적으로 특징을 추상화하는 계층적인 구조를 가집니다. 반면, ViT는 이미지를 패치로 분할한 후, 모든 패치를 동일한 차원의 벡터로 변환하여 단일 스케일에서 처리합니다. 이러한 평탄한 구조는 모델의 구현과 최적화를 더 쉽게 만듭니다.
데이터 의존성: CNN은 비교적 적은 양의 데이터로도 잘 동작하는 경향이 있습니다. 하지만 ViT는 트랜스포머 기반 모델의 특성상, 충분한 양의 데이터가 있어야 제 성능을 발휘합니다. 대규모 데이터셋으로 사전 학습(pre-training)된 ViT는 이미지 분류, 객체 탐지 등 다양한 비전 태스크에서 CNN을 능가하는 성능을 보여줍니다.
ViT의 등장은 이미지 처리 분야의 연구 방향을 완전히 바꾸어 놓았습니다. ViT 이후, 이미지 패치 임베딩, 어텐션 메커니즘, 대규모 사전 학습 등의 아이디어를 기반으로 한 다양한 후속 연구들이 쏟아져 나왔습니다.
이미지 패치 임베딩은 ViT의 첫 번째 단계로, 2차원 이미지를 1차원의 시퀀스 형태로 변환하는 과정입니다. PyTorch에서는 torchvision.models.vision_transformer.PatchEmbed 클래스가 이 역할을 담당합니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class PatchEmbed(nn.Module):
"""
Transforms a 2D image into a sequence of patch embeddings.
"""
def __init__(
self,
img_size: int = 224,
patch_size: int = 16,
in_chans: int = 3,
embed_dim: int = 768,
) -> None:
"""
Args:
img_size: The size of the input image (assuming a square image)
patch_size: The patch size (assuming square patches)
in_chans: The number of input image channels (e.g., 3 for RGB images)
embed_dim: The dimension of the patch embedding vector
"""
super().__init__()
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) * (img_size // patch_size)
self.projection = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Transforms the input image into a sequence of patch embeddings.
Args:
x: Input image (shape: [batch_size, in_chans, img_size, img_size])
Returns:
Sequence of patch embeddings (shape: [batch_size, num_patches, embed_dim])
"""
x = self.projection(x) # [batch_size, embed_dim, num_patches_h, num_patches_w]
x = x.flatten(2) # [batch_size, embed_dim, num_patches]
x = x.transpose(1, 2) # [batch_size, num_patches, embed_dim]
return xPatchEmbed 클래스의 __init__ 메서드에서 가장 중요한 부분은 self.projection = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) 입니다. 이 한 줄의 코드가 이미지 패치 분할과 임베딩을 동시에 수행합니다.
nn.Conv2d: 2D Convolution 연산을 수행하는 PyTorch 레이어입니다.in_chans: 입력 이미지의 채널 수 (RGB 이미지의 경우 3).embed_dim: 출력 임베딩 벡터의 차원 (ViT-Base 모델의 경우 768).kernel_size=patch_size: Convolution 필터(커널)의 크기를 패치 크기와 동일하게 설정합니다.stride=patch_size: 필터가 이미지 위를 이동하는 간격(stride)을 패치 크기와 동일하게 설정합니다.kernel_size와 stride를 patch_size와 동일하게 설정함으로써, Convolution 필터는 이미지를 겹치지 않게, 마치 바둑판처럼 정확하게 패치 크기로 나누는 역할을 합니다. 각 Convolution 필터는 하나의 패치에 대한 정보를 압축하여 하나의 임베딩 벡터를 생성합니다.
PatchEmbed 클래스의 forward 메서드에서는 self.projection(x)를 통해 실제로 이미지 패치 임베딩을 수행합니다.
self.projection(x): 입력 이미지 x ([batch_size, in_chans, img_size, img_size])에 Conv2d 연산을 적용합니다. 출력은 [batch_size, embed_dim, num_patches_h, num_patches_w] 형태가 됩니다. (num_patches_h와 num_patches_w는 각각 이미지의 높이와 너비를 패치 크기로 나눈 값)
x.flatten(2): Conv2d의 출력을 [batch_size, embed_dim, num_patches] 형태로 평탄화(flatten)합니다. num_patches는 총 패치의 개수 (num_patches_h * num_patches_w)입니다.
x.transpose(1, 2): 텐서의 차원을 [batch_size, num_patches, embed_dim] 형태로 바꿉니다. 이는 트랜스포머 인코더의 입력으로 사용하기 위한 형태로, 각 패치 임베딩 벡터가 시퀀스의 한 요소처럼 취급됩니다.
결과적으로, PatchEmbed 클래스는 이미지를 패치로 나누고, 각 패치를 embed_dim 차원의 벡터로 선형 변환(Linear Projection)하여, 트랜스포머 인코더의 입력으로 사용할 수 있는 시퀀스 형태로 만들어 줍니다.
ViT는 이미지를 패치로 분할하고, 각 패치를 마치 텍스트의 단어처럼 취급하여 트랜스포머에 입력합니다. 하지만 트랜스포머는 입력 시퀀스의 순서 정보를 자체적으로 인식하지 못합니다. 따라서 각 패치가 이미지의 어느 위치에 해당하는지를 모델에게 알려주어야 합니다. 이 역할을 수행하는 것이 바로 포지셔널 인코딩(Positional Encoding)입니다.
PyTorch의 VisionTransformer 클래스에서는 학습 가능한 (learnable) 포지셔널 임베딩을 사용합니다. 즉, 각 패치의 위치에 해당하는 고유한 임베딩 벡터를 학습 과정에서 함께 최적화합니다.
class VisionTransformer(nn.Module):
def __init__(self, ..., num_patches, embed_dim, ...):
super().__init__()
# ...
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) # Class token
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim)) # Positional embedding
self.pos_drop = nn.Dropout(p=drop_rate)
# ...
def _pos_embed(self, x):
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1) # Prepend class token
x = x + self.pos_embed # Add positional embedding
return self.pos_drop(x)
def forward(self, x):
x = self.patch_embed(x) # Patch embedding
x = self._pos_embed(x) # Add positional embedding
# ... (Transformer Encoder etc.) ...코드 설명
self.pos_embed (학습 가능한 파라미터): nn.Parameter로 정의되어 학습 과정에서 업데이트됩니다. (1, num_patches + 1, embed_dim) 크기를 가집니다.
num_patches + 1: 패치의 개수에 1을 더한 것은, 이미지 패치 외에 특별한 역할을 하는 클래스 토큰 (class token) 을 위한 공간을 확보하기 위함입니다.embed_dim: 패치 임베딩의 차원과 동일한 차원을 가집니다.embed_dim 차원의 고유한 위치 임베딩 벡터를 할당받습니다._pos_embed 메서드:
x (패치 임베딩 시퀀스)의 맨 앞에 self.cls_token을 추가합니다. cls_token은 배치 크기만큼 복제(expand)되어 모든 이미지에 대해 동일하게 적용됩니다.self.pos_embed 값을 더합니다. PyTorch의 브로드캐스팅(broadcasting) 규칙에 따라, self.pos_embed의 각 위치 임베딩 벡터는 해당 위치의 모든 패치 임베딩 벡터에 자동으로 더해집니다.forward 메서드: forward 메서드에서는 self.patch_embed(x)를 통해 이미지를 패치 임베딩으로 변환한 후, self._pos_embed(x)를 호출하여 포지셔널 임베딩을 추가합니다.정리
ViT는 각 패치(및 클래스 토큰)에 대해 학습 가능한 포지셔널 임베딩을 사용하고, 이를 패치 임베딩에 더하는 방식으로 위치 정보를 모델에 주입합니다. 포지셔널 임베딩은 모델 학습 과정에서 다른 가중치들과 함께 최적화되므로, 데이터에 가장 적합한 형태로 위치 정보를 표현할 수 있게 됩니다.
ViT (Vision Transformer)는 이미지를 텍스트처럼 처리하여 분류와 같은 비전 태스크를 수행하는 모델입니다. PyTorch에서는 torchvision.models.VisionTransformer 클래스를 통해 ViT 모델을 사용할 수 있습니다.
class VisionTransformer(nn.Module):
def __init__(self, ..., embed_dim, depth, num_heads, ...):
super().__init__()
self.patch_embed = PatchEmbed(...) # Image patch embedding
self.cls_token = nn.Parameter(...) # Class token
self.pos_embed = nn.Parameter(...) # Positional embedding
self.pos_drop = nn.Dropout(...)
self.blocks = nn.Sequential(*[
TransformerEncoderLayer(...) for _ in range(depth) # Transformer Encoder blocks
])
self.norm = nn.LayerNorm(embed_dim) # Layer Normalization
self.head = nn.Linear(embed_dim, num_classes) # Classification Head
def forward_features(self, x):
x = self.patch_embed(x) # 1. Patch embedding
x = torch.cat((self.cls_token.expand(x.shape[0], -1, -1), x), dim=1) # 2. Prepend class token
x = x + self.pos_embed # 3. Add positional embedding
x = self.pos_drop(x)
x = self.blocks(x) # 4. Transformer Encoder
x = self.norm(x) # 5. LayerNorm
return x[:, 0] # 6. Return class token
def forward(self, x):
x = self.forward_features(x) # Feature extraction
x = self.head(x) # Classification
return xViT의 핵심 구성 요소:
PatchEmbed (패치 임베딩): 이미지를 여러 개의 작은 패치로 나누고, 각 패치를 고정된 차원의 벡터(임베딩)로 변환합니다. (10.5.2절 참조)cls_token (클래스 토큰): 학습 가능한 파라미터로, 패치 임베딩 시퀀스의 맨 앞에 추가되는 특별한 토큰입니다. 트랜스포머 인코더를 통과한 후, 이 클래스 토큰은 이미지 전체를 대표하는 정보(feature)를 담게 되며, 최종 분류(classification)에 사용됩니다.pos_embed (포지셔널 임베딩): 각 패치(와 클래스 토큰)의 위치 정보를 나타내는 학습 가능한 파라미터입니다. 트랜스포머는 입력 시퀀스의 순서를 자체적으로 알 수 없기 때문에, 포지셔널 임베딩을 통해 위치 정보를 명시적으로 제공해야 합니다. (10.5.3절 참조)blocks (트랜스포머 인코더): 여러 개의 TransformerEncoderLayer가 쌓여서 구성됩니다.
TransformerEncoderLayer: ViT의 핵심 블록으로, 멀티헤드 셀프 어텐션(Multi-Head Self-Attention)과 Feed-Forward Network (FFN)으로 구성됩니다.
norm (Layer Normalization) : Transformer Encoder의 출력에 Layer Normalization을 적용head (Classification Head): 트랜스포머 인코더를 통과한 클래스 토큰을 입력으로 받아, 최종적으로 이미지의 클래스를 예측하는 fully-connected layer입니다.forward 메서드 (전체적인 처리 흐름):
forward_features 메서드:
self.patch_embed(x): 입력 이미지를 패치 임베딩 시퀀스로 변환합니다.self.cls_token)을 패치 임베딩 시퀀스 맨 앞에 추가합니다.self.pos_embed)을 더합니다.self.blocks)를 통과시킵니다.self.norm)을 적용합니다.x[:, 0])만 반환합니다.self.head(x): forward_features에서 반환된 클래스 토큰을 classification head에 통과시켜 최종 예측(분류) 결과를 얻습니다.요약:
ViT는 이미지를 패치로 나누고, 각 패치를 트랜스포머 인코더에 입력하여 이미지 전체의 특징을 추출합니다. 이때, 클래스 토큰과 포지셔널 임베딩을 사용하여 이미지의 전역적인 정보와 패치의 위치 정보를 함께 고려합니다. 최종적으로 클래스 토큰을 사용하여 이미지를 분류합니다.
ViT를 이용하여 CIFAR-10 데이터셋을 훈련하는 간단한 예제를 살펴보겠습니다. 아래 코드는 PyTorch를 사용하여 ViT 모델을 훈련하고, 에폭별 손실(loss)과 정확도(accuracy)를 출력합니다.
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torchvision.models import vit_b_16 # Using vit_b_16 model as an example
from torch.utils.data import DataLoader
# Hyperparameter setup for a simple training run
num_epochs = 5
batch_size = 32
learning_rate = 1e-4
image_size = 224 # ViT input image size
num_classes = 10 # Number of classes in the CIFAR-10 dataset
# Use GPU if available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Data loading and preprocessing (using CIFAR-10 dataset)
transform = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # Normalize with CIFAR-10 statistics
])
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# Create ViT model (not using pretrained weights)
model = vit_b_16(pretrained=False, num_classes=num_classes).to(device)
# Define loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.AdamW(model.parameters(), lr=learning_rate)
# Training loop
for epoch in range(num_epochs):
model.train() # Set the model to training mode
running_loss = 0.0
correct_predictions = 0
total_samples = 0
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
# Forward and backward passes
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Calculate statistics
running_loss += loss.item()
_, predicted = torch.max(outputs, 1) # Select the class with the highest probability
total_samples += labels.size(0)
correct_predictions += (predicted == labels).sum().item()
# Print every 100 batches.
# if (i + 1) % 100 == 0:
# print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
# Print epoch statistics
epoch_loss = running_loss / len(train_loader)
epoch_accuracy = correct_predictions / total_samples * 100
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {epoch_loss:.4f}, Accuracy: {epoch_accuracy:.2f}%')
print('Training finished!')100%|██████████| 170M/170M [00:21<00:00, 8.09MB/s]
/home/sean/anaconda3/envs/DL/lib/python3.10/site-packages/torchvision/models/_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and may be removed in the future, please use 'weights' instead.
warnings.warn(
/home/sean/anaconda3/envs/DL/lib/python3.10/site-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and may be removed in the future. The current behavior is equivalent to passing `weights=None`.
warnings.warn(msg)Epoch [1/5], Step [100/1563], Loss: 2.1349
Epoch [1/5], Step [200/1563], Loss: 1.8978
Epoch [1/5], Step [300/1563], Loss: 1.9483
Epoch [1/5], Step [400/1563], Loss: 2.0783
Epoch [1/5], Step [500/1563], Loss: 1.7614
Epoch [1/5], Step [600/1563], Loss: 1.8051
Epoch [1/5], Step [700/1563], Loss: 1.7448
Epoch [1/5], Step [800/1563], Loss: 1.8347
Epoch [1/5], Step [900/1563], Loss: 1.8127
Epoch [1/5], Step [1000/1563], Loss: 1.7755
Epoch [1/5], Step [1100/1563], Loss: 1.6506
Epoch [1/5], Step [1200/1563], Loss: 1.7523
Epoch [1/5], Step [1300/1563], Loss: 1.5987
Epoch [1/5], Step [1400/1563], Loss: 1.6078
Epoch [1/5], Step [1500/1563], Loss: 1.7110
Epoch [1/5], Loss: 1.8429, Accuracy: 29.66%
Epoch [2/5], Step [100/1563], Loss: 1.4902
Epoch [2/5], Step [200/1563], Loss: 1.5161
Epoch [2/5], Step [300/1563], Loss: 1.4563
Epoch [2/5], Step [400/1563], Loss: 1.5858
Epoch [2/5], Step [500/1563], Loss: 1.6702
Epoch [2/5], Step [600/1563], Loss: 1.5833
Epoch [2/5], Step [700/1563], Loss: 1.4790
Epoch [2/5], Step [800/1563], Loss: 1.6507
Epoch [2/5], Step [900/1563], Loss: 1.6017
Epoch [2/5], Step [1000/1563], Loss: 1.5102
Epoch [2/5], Step [1100/1563], Loss: 1.2946
Epoch [2/5], Step [1200/1563], Loss: 1.3225
Epoch [2/5], Step [1300/1563], Loss: 1.9922
Epoch [2/5], Step [1400/1563], Loss: 1.3685
Epoch [2/5], Step [1500/1563], Loss: 1.4852
Epoch [2/5], Loss: 1.5410, Accuracy: 42.69%
Epoch [3/5], Step [100/1563], Loss: 1.2692
Epoch [3/5], Step [200/1563], Loss: 1.1648
Epoch [3/5], Step [300/1563], Loss: 1.2412
Epoch [3/5], Step [400/1563], Loss: 1.6217
Epoch [3/5], Step [500/1563], Loss: 1.3776
Epoch [3/5], Step [600/1563], Loss: 1.2591
Epoch [3/5], Step [700/1563], Loss: 1.4333
Epoch [3/5], Step [800/1563], Loss: 1.3301
Epoch [3/5], Step [900/1563], Loss: 1.3536
Epoch [3/5], Step [1000/1563], Loss: 1.4488
Epoch [3/5], Step [1100/1563], Loss: 1.3179
Epoch [3/5], Step [1200/1563], Loss: 1.0684
Epoch [3/5], Step [1300/1563], Loss: 1.6526
Epoch [3/5], Step [1400/1563], Loss: 1.1815
Epoch [3/5], Step [1500/1563], Loss: 1.3683
Epoch [3/5], Loss: 1.3836, Accuracy: 49.23%
Epoch [4/5], Step [100/1563], Loss: 1.2601
Epoch [4/5], Step [200/1563], Loss: 1.3277
Epoch [4/5], Step [300/1563], Loss: 1.1337
Epoch [4/5], Step [400/1563], Loss: 1.2273
Epoch [4/5], Step [500/1563], Loss: 1.7351
Epoch [4/5], Step [600/1563], Loss: 1.3826
Epoch [4/5], Step [700/1563], Loss: 1.2639
Epoch [4/5], Step [800/1563], Loss: 1.5757
Epoch [4/5], Step [900/1563], Loss: 1.0702
Epoch [4/5], Step [1000/1563], Loss: 1.3986
Epoch [4/5], Step [1100/1563], Loss: 1.1105
Epoch [4/5], Step [1200/1563], Loss: 1.2621
Epoch [4/5], Step [1300/1563], Loss: 1.4261
Epoch [4/5], Step [1400/1563], Loss: 1.3028
Epoch [4/5], Step [1500/1563], Loss: 1.9051
Epoch [4/5], Loss: 1.2850, Accuracy: 52.98%
Epoch [5/5], Step [100/1563], Loss: 0.9517
Epoch [5/5], Step [200/1563], Loss: 0.9844
Epoch [5/5], Step [300/1563], Loss: 1.2391
Epoch [5/5], Step [400/1563], Loss: 1.3588
Epoch [5/5], Step [500/1563], Loss: 0.9441
Epoch [5/5], Step [600/1563], Loss: 1.1711
Epoch [5/5], Step [700/1563], Loss: 1.1687
Epoch [5/5], Step [800/1563], Loss: 1.0097
Epoch [5/5], Step [900/1563], Loss: 0.9899
Epoch [5/5], Step [1000/1563], Loss: 1.3289
Epoch [5/5], Step [1100/1563], Loss: 1.5510
Epoch [5/5], Step [1200/1563], Loss: 0.9139
Epoch [5/5], Step [1300/1563], Loss: 0.9221
Epoch [5/5], Step [1400/1563], Loss: 1.3378
Epoch [5/5], Step [1500/1563], Loss: 1.1785
Epoch [5/5], Loss: 1.2116, Accuracy: 55.78%
Training finished!이 코드는 ViT 모델의 동작 방식을 보여주기 위한 간단한 예제 입니다. 실제 ViT는 ImageNet과 같은 대규모 데이터셋 에서 사전 학습(pre-training)된 후, 특정 태스크(예: CIFAR-10 분류)에 맞게 미세 조정(fine-tuning)하는 방식으로 사용될 때 훨씬 더 좋은 성능을 보입니다. 여기서는 단순하게 훈련이 가능한 여부만을 확인합니다.
ViT의 의의 및 영향
ViT는 이미지 분류 태스크에서 CNN을 능가하는 성능을 보여주면서, 컴퓨터 비전 분야에 큰 반향을 일으켰습니다. 특히, JFT-300M과 같이 3억 장 이상의 대규모 이미지 데이터셋으로 사전 학습했을 때 그 진가를 발휘했습니다. 이는 다음의 두 가지 중요한 시사점을 던져주었습니다.
Scalability (확장성): ViT는 데이터셋의 크기가 커질수록 성능이 지속적으로 향상되는 뛰어난 확장성을 보여주었습니다. 이는 CNN 기반 모델들이 일정 규모 이상의 데이터셋에서는 성능 향상이 정체되거나 오히려 저하되는 현상과는 대조적입니다. ViT의 이러한 특징은, 앞으로 더 많은 데이터를 활용하여 더욱 강력한 비전 모델을 구축할 수 있는 가능성을 열었습니다.
Transformer의 범용성: ViT는 자연어 처리(NLP) 분야에서 널리 사용되던 트랜스포머 아키텍처가 이미지 처리 분야에서도 효과적일 수 있음을 입증했습니다. 이는 하나의 아키텍처로 다양한 모달리티(modality, 텍스트, 이미지, 음성 등)를 처리할 수 있는 멀티모달(multimodal) 모델 연구의 기폭제가 되었습니다.
ViT의 성공은 이후 CLIP (Contrastive Language-Image Pre-training)과 같은 멀티모달 모델 개발의 중요한 기반이 되었습니다. CLIP은 ViT의 이미지 인코더와 트랜스포머 기반의 텍스트 인코더를 결합하여, 이미지와 텍스트를 하나의 통합된 공간에 표현하는 방식을 학습합니다. 이를 통해, 이미지에 대한 텍스트 설명을 생성하거나, 텍스트 설명을 기반으로 이미지를 검색하는 등 다양한 응용이 가능해졌습니다.
Google Research 팀이 제안하고 훈련시킨 ViT-22B는 이미지 분류에서 CNN을 능가하는 성능을 보이면서, 컴퓨터 비전 분야에 큰 반향을 일으켰습니다. ViT-22B는 모델과 데이터의 크기를 확장하는 것이 성능 향상의 핵심 요인 중 하나임을 입증했습니다. 220억 개의 파라미터라는 압도적인 크기와, 수십억 장의 이미지로 구성된 초대규모 데이터셋으로 학습된 ViT-22B는 이전에는 상상하기 어려웠던 수준의 성능을 달성하며 비전 AI의 새로운 지평을 열었습니다.
탄생 배경: 스케일링 법칙과 거대 언어 모델의 성공
ViT-22B의 등장은 자연어 처리(NLP) 분야에서 거대 언어 모델(Large Language Model, LLM)이 보여준 놀라운 성공과 깊은 관련이 있습니다. GPT-3와 같은 LLM은 모델의 크기(파라미터 수)와 데이터의 양을 늘릴수록 성능이 꾸준히 향상되는 스케일링 법칙(scaling law)을 따르는 것으로 나타났습니다. 이러한 경향은 “더 큰 것이 더 좋다(bigger is better)”라는 믿음을 확산시켰고, 비전 분야에서도 유사한 시도가 이루어지게 되었습니다.
ViT는 트랜스포머 아키텍처를 기반으로 하기 때문에, LLM에서 검증된 스케일링 전략을 적용하기에 용이했습니다. 이미지 패치를 텍스트 토큰처럼 처리하는 ViT의 특성상, 모델의 구조를 크게 변경하지 않고도 파라미터 수를 늘리고 더 많은 데이터를 사용하여 학습할 수 있었기 때문입니다.
ViT-22B의 구조 및 특징
ViT-22B는 기본적으로 ViT의 아키텍처를 따르지만, 규모 면에서 차원이 다릅니다.
거대한 모델 크기: 220억 개의 파라미터를 가진 ViT-22B는, ViT-Base (8600만 개), ViT-Large (3억 700만 개), ViT-Huge (6억 3200만 개)와 비교했을 때 압도적으로 큰 규모를 자랑합니다. 이는 모델이 훨씬 더 복잡하고 미묘한 이미지 특징을 포착하고, 더 많은 지식을 내재화할 수 있음을 의미합니다.
초대규모 데이터셋: ViT-22B는 수십억 장 이상의 이미지로 구성된 비공개 데이터셋(JFT-4B 등)으로 학습되었습니다. 이러한 대규모 데이터는 모델이 일반화 성능(generalization performance)을 극대화하고, 다양한 이미지 분포를 포괄적으로 학습하는 데 필수적입니다.
향상된 성능: ViT-22B는 이미지 분류, 객체 탐지, 이미지 분할 등 다양한 비전 벤치마크에서 기존의 어떤 모델보다 뛰어난 성능(SOTA, State-Of-The-Art)을 기록했습니다. 이는 모델의 크기와 데이터의 양이 성능에 미치는 긍정적인 영향을 명확하게 보여줍니다.
ViT-22B 훈련의 어려움과 시사점
ViT-22B와 같은 초대규모 모델을 훈련하는 것은 일반적인 연구 환경에서는 거의 불가능합니다. 수백, 수천 개의 GPU 또는 TPU와 같은 고가의 특수 하드웨어가 필요하며, 훈련 시간도 몇 주에서 몇 달까지 소요될 수 있습니다. 또한, 엄청난 양의 데이터를 저장하고 처리하는 인프라 구축도 큰 과제입니다.
ViT-22B의 등장은 ViT 아키텍처의 확장 가능성(scalability)을 입증했지만, 동시에 효율성(efficiency)에 대한 고민을 던져주었습니다. 모델의 크기가 커질수록 성능은 향상되지만, 훈련 및 추론(inference)에 필요한 컴퓨팅 자원과 에너지 소비량도 기하급수적으로 증가하기 때문입니다. 따라서, 앞으로의 연구는 모델의 성능을 유지하면서도 효율성을 높이는 방향으로 진행될 것으로 예상됩니다.
Meta AI (Facebook AI Research, FAIR) 팀이 제안한 MAE(Masked Autoencoder)는 레이블이 없는 대규모 이미지 데이터셋을 활용하여 강력한 이미지 표현(representation)을 학습하는 자기 지도 학습(self-supervised learning) 방법입니다. ViT를 기반으로 하는 MAE는 이미지의 상당 부분을 무작위로 가리고(masking), 가려진 부분을 복원하도록 모델을 훈련시킵니다. MAE v3는 이러한 MAE의 최신 버전으로, 여러 가지 개선 사항을 통해 성능과 효율성을 더욱 향상시켰습니다.
MAE의 작동 원리
MAE의 핵심 아이디어는 사람이 “빈칸 채우기” 문제를 풀듯이, 이미지의 일부 정보만 보고도 전체 이미지를 이해하고 복원하도록 모델을 학습시키는 것입니다.
입력 이미지의 무작위 마스킹: 입력 이미지의 상당 부분(예: 75%)을 무작위로 가립니다. 이때, 이미지 패치 단위로 마스킹을 수행합니다.
인코딩 (Encoding): 가려지지 않은, 즉 보이는 패치들만 ViT 인코더에 입력하여 특징 벡터를 추출합니다.
디코딩 (Decoding): 인코더의 출력(보이는 패치들의 특징)과 마스킹된 패치에 대한 정보를 함께 사용하여 원래 이미지를 복원합니다. 이때, 디코더는 가벼운(lightweight) Transformer 블록으로 구성하여 계산 효율성을 높입니다.
복원 손실 (Reconstruction Loss): 복원된 이미지와 원본 이미지 간의 픽셀 수준 차이(예: Mean Squared Error, MSE)를 계산하고, 이 차이를 최소화하는 방향으로 모델(인코더와 디코더)을 학습합니다.
MAE v3의 구조적 개선
MAE v3는 다음과 같은 주요 개선 사항을 통해 이전 버전보다 더 나은 성능과 효율성을 달성했습니다.
향상된 마스킹 전략: 초기 MAE에서는 단순히 무작위로 패치를 마스킹했지만, MAE v3에서는 더 정교한 마스킹 전략을 사용합니다. 예를 들어, 이미지의 의미 있는 영역(객체의 경계 등)을 더 잘 보존하도록 마스킹하거나, 다양한 크기의 패치를 마스킹하는 등의 방법을 적용할 수 있습니다.
최적화된 인코더-디코더 구조
스케일 확장: ViT-L/16, ViT-H/16에서 ViT-g/14(파라미터 25억개)까지 모델 스케일을 확장하였습니다.
MAE의 장점과 의의
MAE는 다음과 같은 장점을 통해 자기 지도 학습 분야에서 주목받고 있습니다.
레이블이 필요 없는 학습: MAE는 레이블이 없는 대규모 이미지 데이터셋을 활용하여 사전 학습(pre-training)을 수행할 수 있습니다. 이는 레이블을 수작업으로 생성하는 데 드는 비용과 시간을 절약하고, 더 많은 데이터를 활용할 수 있게 해줍니다.
강력한 표현 학습: MAE는 이미지의 상당 부분이 가려진 상태에서도 이미지를 복원하는 과정을 통해, 이미지의 구조, 의미, 맥락 등을 파악하는 능력을 키웁니다. 이러한 능력은 이미지 분류, 객체 탐지, 분할 등 다양한 다운스트림 태스크(downstream task)에서 좋은 성능을 내는 데 도움이 됩니다.
전이 학습(Transfer Learning) 용이성: MAE로 사전 학습된 모델은 다양한 태스크에 미세 조정(fine-tuning)하여 사용할 수 있습니다. 이는 레이블이 부족한 태스크에서도 좋은 성능을 얻을 수 있게 해줍니다.
결론
MAE는 “빈칸 채우기”라는 직관적인 아이디어를 통해, 레이블 없이도 강력한 이미지 표현을 학습할 수 있는 효과적인 방법을 제시했습니다. MAE v3는 이러한 MAE의 장점을 더욱 발전시켜, 더 높은 성능과 효율성을 달성하며 자기 지도 학습 연구의 발전을 이끌고 있습니다.
2021년, OpenAI는 “Learning Transferable Visual Models From Natural Language Supervision” 논문을 통해 CLIP (Contrastive Language-Image Pre-training) 모델을 발표했습니다. CLIP은 이미지와 텍스트, 두 가지 다른 모달리티(modality)를 하나의 공유된 공간(shared space)에 표현하는 방법을 학습함으로써, 멀티모달 학습 분야에 혁신적인 발전을 가져왔습니다.
CLIP의 핵심은 이미지 인코더(Image Encoder)와 텍스트 인코더(Text Encoder), 두 개의 독립적인 인코더로 구성된 듀얼 인코더 구조입니다.
이 두 인코더는 대조 학습(contrastive learning)을 통해 훈련됩니다.
CLIP 훈련의 핵심: 대조 학습 (Contrastive Learning)
CLIP 훈련의 핵심은 대규모 이미지-텍스트 쌍 데이터셋을 사용하는 대조 학습입니다.
코드 예시
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class CLIP(nn.Module):
def __init__(self, image_encoder, text_encoder, embed_dim):
super().__init__()
self.image_encoder = image_encoder
self.text_encoder = text_encoder
self.image_projection = nn.Linear(image_encoder.output_dim, embed_dim)
self.text_projection = nn.Linear(text_encoder.output_dim, embed_dim)
self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07)) # Learnable scale parameter
def forward(self, images, texts):
# 1. Image encoding
image_features = self.image_encoder(images) # [batch_size, image_encoder.output_dim]
image_embeddings = self.image_projection(image_features) # [batch_size, embed_dim]
image_embeddings = F.normalize(image_embeddings, dim=-1) # L2 normalization
# 2. Text encoding
text_features = self.text_encoder(texts) # [batch_size, text_encoder.output_dim]
text_embeddings = self.text_projection(text_features) # [batch_size, embed_dim]
text_embeddings = F.normalize(text_embeddings, dim=-1) # L2 normalization
# 3. Similarity calculation
logits_per_image = self.logit_scale.exp() * image_embeddings @ text_embeddings.t() # [batch_size, batch_size]
logits_per_text = logits_per_image.t() # [batch_size, batch_size]
return logits_per_image, logits_per_text
def contrastive_loss(logits_per_image, logits_per_text):
"""
Calculates the Contrastive Loss
"""
batch_size = logits_per_image.shape[0]
labels = torch.arange(batch_size).to(logits_per_image.device) # Correct labels (diagonal: same pair)
loss_i = F.cross_entropy(logits_per_image, labels) # Loss based on image
loss_t = F.cross_entropy(logits_per_text, labels) # Loss based on text
return (loss_i + loss_t) / 2 # Average lossCLIP의 이미지 인코더는 이미지를 입력받아 고정된 차원의 임베딩 벡터로 변환합니다. 초기 CLIP 논문에서는 ResNet과 ViT(Vision Transformer)를 모두 실험했습니다.
실험 결과, ViT 기반 인코더가 ResNet 기반 인코더보다 더 좋은 성능을 보였습니다. 특히, 모델과 데이터의 크기가 커질수록 ViT의 성능 향상 폭이 더 컸습니다.
CLIP의 텍스트 인코더는 텍스트 설명을 입력받아 이미지 인코더와 동일한 차원의 임베딩 벡터로 변환합니다. 초기 CLIP 논문에서는 Transformer 기반의 텍스트 인코더를 사용했습니다.
CLIP의 가장 큰 특징 중 하나는 별도의 미세 조정(fine-tuning) 없이도 다양한 이미지 분류 태스크에서 뛰어난 성능을 보이는 제로샷(zero-shot) 전이 능력입니다.
Zero-shot 전이가 가능한 이유
CLIP은 대규모 이미지-텍스트 쌍 데이터셋으로 대조 학습을 수행하는 과정에서, 이미지와 텍스트를 동일한 의미 공간(semantic space)에 표현하는 방법을 학습합니다. 즉, CLIP은 이미지와 텍스트 간의 의미적인 관련성을 파악하는 능력을 갖게 됩니다.
Zero-shot 분류 과정
분류할 클래스(class)에 대한 텍스트 설명을 준비합니다. 예를 들어, CIFAR-10 데이터셋의 경우, “a photo of a cat”, “a photo of a dog”, …, “a photo of a truck”과 같은 텍스트 설명을 준비합니다.
텍스트 인코더를 사용하여 각 텍스트 설명을 임베딩합니다.
주어진 이미지를 이미지 인코더를 사용하여 임베딩합니다.
이미지 임베딩과 각 텍스트 임베딩 간의 유사도(예: 코사인 유사도)를 계산합니다.
가장 높은 유사도를 갖는 텍스트 설명에 해당하는 클래스를 이미지의 예측 클래스로 선택합니다.
Zero-shot 전이의 의미
Zero-shot 전이는 모델이 학습 과정에서 전혀 보지 못한 새로운 클래스나 태스크에 대해서도, 추가적인 학습이나 미세 조정(fine-tuning) 없이 바로 적용할 수 있는 능력을 의미합니다. 이는 기존의 지도 학습 방식이 특정 태스크에 특화된 레이블이 있는 데이터를 필요로 하는 것과 대조적입니다.
Zero-shot 전이의 핵심은 유연성입니다. 예를 들어, 이미지 분류 모델을 학습시킬 때 “고양이”와 “강아지” 클래스에 대한 데이터만 사용했더라도, “기린”이나 “코끼리”와 같이 학습 데이터에 없던 클래스에 대한 이미지가 주어져도, “기린 사진”, “코끼리 사진”과 같은 자연어 설명만 제공하면 모델이 이미지를 올바르게 분류할 수 있습니다. 이처럼 새로운 클래스나 태스크에 대한 데이터가 전혀 없는 상황에서도, 자연어 설명을 통해 모델의 일반화 능력을 극대화할 수 있다는 것이 zero-shot 전이의 가장 큰 강점입니다.
또한, Zero-shot 전이는 범용성을 제공합니다. 이미지 분류뿐만 아니라, 이미지 검색, 이미지 캡셔닝, 객체 탐지(object detection), 시각적 질의응답(Visual Question Answering, VQA) 등 다양한 멀티모달 태스크에 적용될 수 있습니다. 예를 들어, 이미지 검색 시스템에서 “빨간색 스포츠카”와 같은 텍스트 쿼리를 입력하면, 모델은 “빨간색 스포츠카”에 해당하는 이미지를 데이터베이스에서 찾아낼 수 있습니다. 이는 모델이 이미지와 텍스트 간의 의미적 연결 관계를 이해하고 있기 때문에 가능한 것입니다. 이처럼 하나의 모델을 다양한 태스크에 활용할 수 있다는 점은 시간과 자원을 절약하고, 인공지능 시스템의 활용도를 높이는 데 크게 기여합니다.
CLIP의 영향
CLIP은 제로샷 전이 능력을 통해 멀티모달 학습의 새로운 가능성을 제시했습니다. 이후, CLIP의 아이디어를 기반으로 한 다양한 후속 연구들이 진행되었으며, DALL-E, Stable Diffusion과 같은 이미지 생성 모델, 그리고 GPT-4V와 같은 대규모 멀티모달 모델 개발에 큰 영향을 미쳤습니다.
Contrastive Learning은 레이블이 없는 데이터에서 표현(representation)을 학습하는 강력한 방법론입니다. 특히, 이미지와 텍스트와 같이 서로 다른 모달리티(modality)를 연결하는 멀티모달 학습에서 뛰어난 성과를 보여주고 있습니다. 이 딥다이브에서는 Contrastive Learning의 기본 원리, 다양한 방법론, 그리고 Contrastive Learning을 기반으로 이미지와 텍스트를 연결하는 획기적인 모델인 CLIP (Contrastive Language-Image Pre-training)을 심층적으로 분석합니다.
Contrastive Learning의 핵심 아이디어는 유사한 샘플 쌍(positive pair)은 임베딩 공간에서 가깝게, 유사하지 않은 샘플 쌍(negative pair)은 멀리 떨어지도록 표현을 학습하는 것입니다.
Contrastive Learning은 일반적으로 다음과 같은 단계를 거칩니다.
다양한 Contrastive Loss 함수가 제안되었으며, 대표적인 예시는 다음과 같습니다.
InfoNCE Loss (Noise Contrastive Estimation): Cross-entropy loss와 유사한 형태로, positive pair에 대한 softmax 확률을 최대화합니다.
\(L = -\log \frac{\exp(\text{sim}(z_i, z_j) / \tau)}{\sum_{k=1}^{2N} \mathbb{1}_{[k \neq i]} \exp(\text{sim}(z_i, z_k) / \tau)}\)
NT-Xent Loss (Normalized Temperature-scaled Cross Entropy Loss): InfoNCE Loss의 변형으로, SimCLR 논문에서 제안되었습니다.
Triplet Loss: Anchor, Positive, Negative 샘플을 사용하여, Anchor와 Positive 간의 거리가 Anchor와 Negative 간의 거리보다 작도록 학습합니다.
\(L = \max(0, d(a, p) - d(a, n) + m)\)
CLIP은 OpenAI에서 개발한 모델로, Contrastive Learning을 사용하여 이미지와 텍스트를 연결하는 강력한 멀티모달 표현을 학습합니다.
Contrastive Learning은 레이블이 없는 데이터를 활용하여 강력한 표현을 학습하는 효과적인 방법론입니다. 특히, CLIP은 Contrastive Learning을 멀티모달 학습에 성공적으로 적용하여, 이미지와 텍스트를 연결하는 새로운 지평을 열었습니다. Contrastive Learning과 CLIP은 앞으로도 다양한 분야에서 활용될 것으로 기대됩니다.
참고 문헌:
기본 문제
응용 문제
blip-image-captioning-base 모델 활용).심화 문제
VQA 모델 구조:
graph LR
subgraph VQA Model
A[Image] --> B(Image Encoder - CNN)
C[Question Text] --> D(Text Encoder - RNN/Transformer)
B --> E(Fusion Module)
D --> E
E --> F(Decoder - RNN/Transformer)
F --> G(Answer)
endCLIP 학습 방식 및 장점:
Hugging Face Transformers Image Captioning 코드:
from transformers import pipeline
captioner = pipeline("image-to-text", model="nlpconnect/vit-gpt2-image-captioning") # 또는 "blip-image-captioning-base"
image_path = "path/to/your/image.jpg" # 이미지 파일 경로
caption = captioner(image_path)[0]['generated_text']
print(caption)멀티모달 퓨전 방법:
Cross-Modal Attention:
텍스트 기반 이미지 생성 모델 (DALL-E, Stable Diffusion 등):
CLIP (Learning Transferable Visual Models From Natural Language Supervision): 이미지와 텍스트를 연결하는 멀티모달 표현 학습 방법인 CLIP의 원 논문. https://arxiv.org/abs/2103.00020
ViT (An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale): CNN 없이 Transformer 구조만으로 이미지 분류에서 뛰어난 성능을 보인 ViT 원 논문. https://arxiv.org/abs/2010.11929
DALL-E (Zero-Shot Text-to-Image Generation): 텍스트 설명을 기반으로 이미지를 생성하는 DALL-E 모델 논문. https://arxiv.org/abs/2102.12092
MAE (Masked Autoencoders Are Scalable Vision Learners): 이미지의 일부를 가리고 복원하는 방식으로 비전 표현을 학습하는 MAE 논문. https://arxiv.org/abs/2111.06377
Visual Question Answering (VQA): 초기 VQA 연구 중 하나로, VQA 데이터셋과 baseline 모델 제시. https://arxiv.org/abs/1505.00468
Show, Attend and Tell (Neural Image Caption Generation with Visual Attention): 어텐션 메커니즘을 이미지 캡셔닝에 처음 도입한 논문. https://arxiv.org/abs/1502.03044
Multimodal Machine Learning: A Survey and Taxonomy: 멀티모달 머신러닝에 대한 포괄적인 survey 논문. https://arxiv.org/abs/1705.09406
A Tutorial on Multimodal Deep Learning, Jiquan Ngiam: NeurIPS 2011의 멀티모달 딥러닝 튜토리얼 (영상). https://www.youtube.com/watch?v=cR_ACqfF-bY&list=PL_45CaSOtPzL-HWxMcnr02KvmP9Gq-xdb
CMU Multimodal Machine Learning Course (11-777, Spring 2023), Louis-Philippe Morency: 카네기 멜론 대학교 멀티모달 머신러닝 강의 자료. https://cmu-multicomp-lab.github.io/mmml-course/spring2023/
A Comprehensive Survey on Deep Multimodal Learning: 2022년 멀티모달 딥러닝 survey 논문. https://arxiv.org/abs/2204.11984
arXiv: 최신 멀티모달 학습 연구 논문 검색. “multimodal learning”, “vision-language” 등 키워드 활용. https://arxiv.org/
Hugging Face Transformers Multimodal Documentation: Hugging Face Transformers 라이브러리의 멀티모달 모델 문서. https://huggingface.co/docs/transformers/main/en/model_doc/auto#multimodal-models